Chef vs Puppet is one of the biggest name in system administration and information technology. Both tools help IT experts to maintain a consistent configuration in all servers. It is very difficult to compare and differentiate both chef and puppet is quite difficult, and decide to choose and who is best for you to use. Puppet or Chef can handle database connection strings where you have a different one for dev, test, and prod.
Both tools can handle these type of work as well.
In this blog I will try to provide you information from all aspect which going to help you to choose between Puppet vs Chef. Discuss everything from the comparison to differences, pros and cons also. This guide is definitely going to help you in your decision of which server to work with. Let’s start-
What is Chef?
Chef is an open-source and code-driven configuration management tool used to transform infrastructure into code. It is well-known for automate how infrastructure is deployed, configured, and managed. Chef can also operate in the cloud, on premises, or even in a hybrid format that comfortable for each individual’s needs.
What is Puppet?
Puppet is another open-source configuration management tool, which is deemed to be the industry standard for configuration management. This tool is designed in a simple way that most users can learn, but it is complex enough to handle difficult level tasks and infrastructure.
System administrators and IT professionals are able to do a variety of tasks like managing large infrastructures to maintenance of the desired states of nodes.
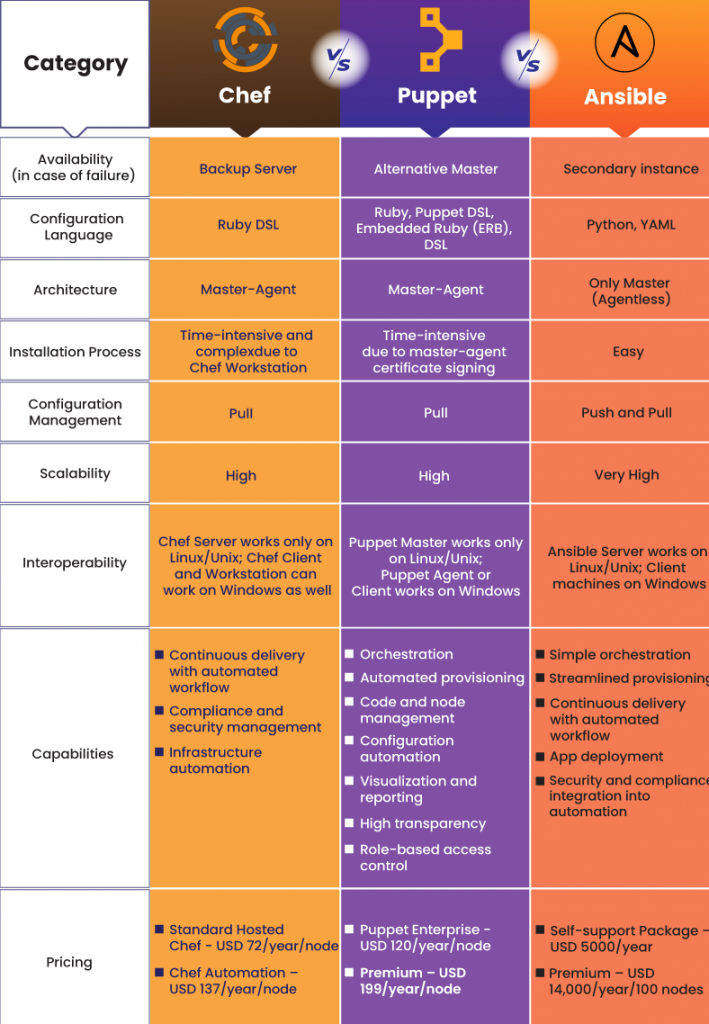
Chef vs Puppet: Important Differences and Similarities
Chef and Puppet both are very promising configuration management software tools, we are here to discuss some of their differences and similarities. Both the tools are simple to use and capabilities to automate complex high level IT application environment.
This differences are on the basis of different factors such as Availability, Configuration Language, Setup and Installation, Ease of Management, Scalability, Interoperability, Tool Capabilities and Pricing. These are:
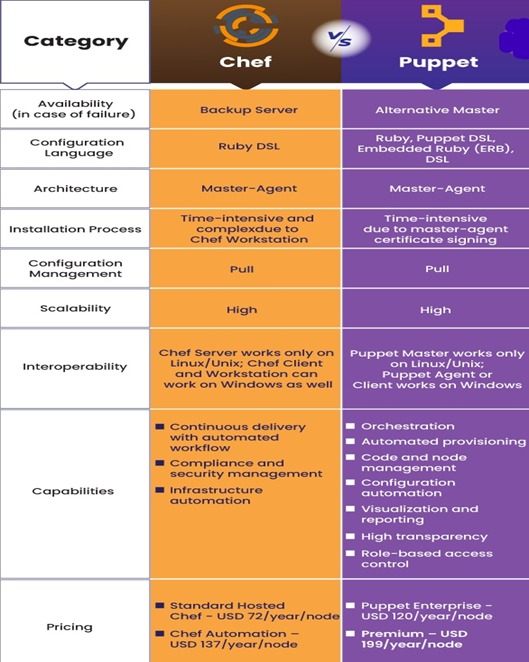
Reports says, IT departments with a strong DevOps workflow deploy software 200 times more frequently, with 3000 times faster lead times, recover 28 times faster, and have three times lower change failure rates.
Final words
Here comes the main question that How to choose between Chef and Puppet, and the answer is it totally depends on the user’s requirements and purpose for which it going to be used.
No matter what you use at the end but decision is especially from the ones who will end up working with the tool. Someone with the same background might find it more suitable to use Puppet or Chef, before taking the decision also consider the premium features from each tool. At the end, features will help your organization in growth or fall.
Pricing is another factor which included but prices fluctuates a lot with time, and it varies depending on each customer needs.
At last both tools have their own advantages and categories in which they are better than the other. My only intention here is to help you in your decision making. So, it is necessary that you choose the appropriate tool which can be fitted according to your needs.
I hope this blog is helpful for you, and if you want to learn more depth knowledge about Chef and Puppet, I would suggest you DevOpsSchool, One of the best institute for training and certification online.
Thank you !!