SOFTWARE CONFIGURATION MANAGEMENT CONTROL TOOLS
Software Configuration Management Tools Blog
Welcome to the Software Configuration Management Tools Discussion Blog. Featured below are links to the most widely used SCM tools available on the market. Which tool has your origination implemented? How well does your tool funtion compared with others you have utilized in the past?
cmtoolsblog.blogspot.com/
PROJECT FOR APACHE ANT, APACHE MAVEN AND GIT
Create a three directory as below in repo as above; Directory Layout as below
harsha
…………..src
…………..test
…………..build.xml
…………..pom.xml
satya
…………..src
…………..test
…………..build.xml
…………..pom.xml
rajesh
…………..src
…………..test
…………..build.xml
…………..pom.xml
Masterbuild.xml
Masterpom.xml
lib
…………..build1
…………..build2
…………..build3
Using Ant
> Each sub directory, add 5 sample java program under “src” eg. under harsha/src.
> Each sub directory, add 5 sample junit test under “test” e.g under rajesh/test.
> Each sub directory has Apache ant build.xml and pom.xml
> Write a Masterbuild.xml which internally call 3 build.xml in the subdirectory and
> compile the source code and run the junit test cases.
> Package each subdirectory src code into jar
> Upload to github.com/microsoft-scmgalaxy/buildrelease3 under “lib/v1-2-3” folder
Using Maven
> Write a Masterpom.xml which internally call 3 pom.xml in the subdirectory and
> compile the source code and run the junit test cases.
> Package each subdirectory src code into jar
> Upload to github.com/microsoft-scmgalaxy/buildrelease3 under “lib/build1” folder
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
OFFERINGS/ACTIVITIES/PRACTICES UNDER SCM/BUILD/RELEASE/DEPLOYMENT
I am in the process of making a list of Offerings/Activities/Practices under SCM/build/release/Deployment area.
Can some someone please suggest some of those Offerings/Activities/Practices which come under SCM/build/release/Deployment.
i have attached a some of the listing in the document.
NAME OF THE TEAM WHICH HAS CM, BUILD, RELEASE, APPOPP AND DB ENGINEER
Hello Folks,
I am looking for ideal NAME OF THE TEAM which has CM, Build, Release, AppOpp Support and Database engineers. Few people Suggested that it should be DevOps and some of them voted for EnterpriceAppOps Team. What is the naming convention is being used in your company? Please comment for new name as well if you have some idea.
ESCAPING A PASSWORD USING MYSQLDUMP CONSOLE
when you use the quotes, make sure there is no space :
between -p and ‘PASSWORD’ or
between –password= and ‘PASSWORD’
correct:
mysql -u root -p’PASSWORD’
mysql -u root –password=’PASSWORD’
does not work:
mysql -u root -p ‘PASSWORD’
mysql -u root –password = ‘PASSWORD’
you can also define a variable and then use it for the command (still with no spaces in between) MSQLPWD=’PASSWORD’
mysql -u root -p$MSQLPWD
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
RELEASE VERSION PORTAL
Hi,
We have a complex product architecture having multiple integrated component making a complete solution.
Each component has its own development team and which provide their delivery to release management team
We have catered the version numbering system where all components are sent under one version in incremental manner.
Now in order to provide the high level visibility to the management about what version of which component is running in QA staging and prod i need to have url based dashboard.
How can achieve this using any simple free tool which enable the font end data form entry , and when someone click on specific version hyperlink it should redirect to release notes of that version in SharePoint.
We tried creating list in SharePoint but it didn’t work as we need environment name as columns and components as rows against which we have to enter version number in the grid table as hyperlinks.
something like
QA staging Prod
Component A 1.7.4 4.24.4 1.4.5
Component B 3.46.5 3.5.7 3.5.7
Component C 3.6.5 3.5.7 2.6.7
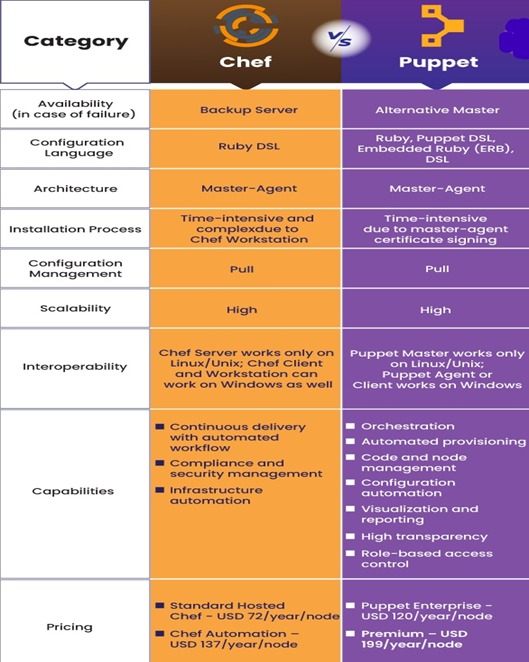
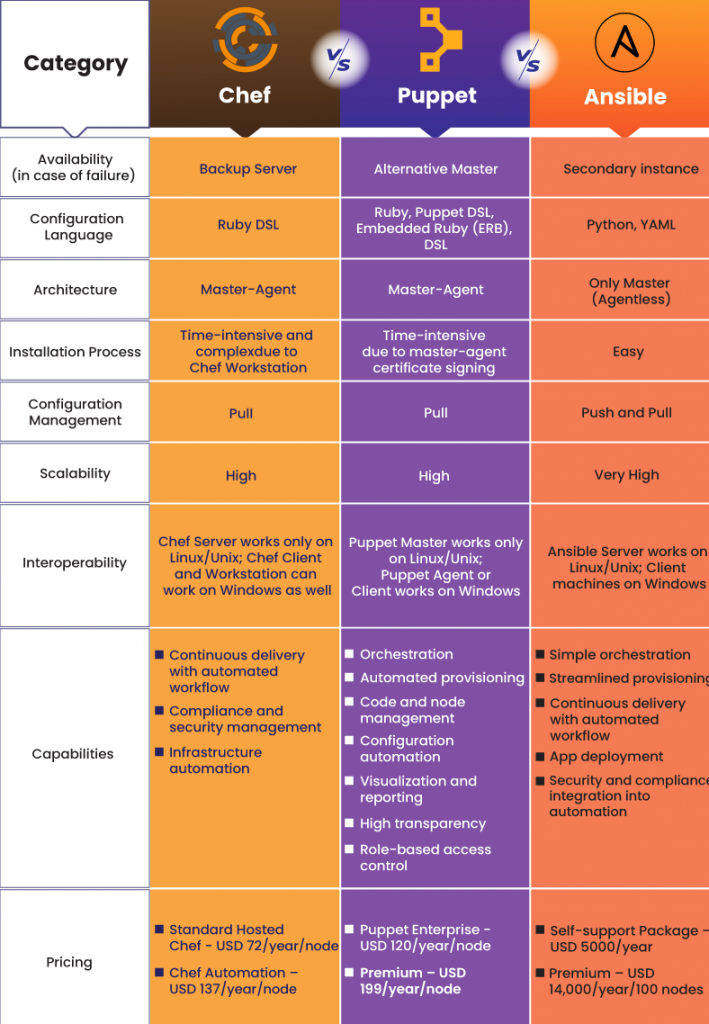
PUPPET
As anyone worked on puppet Configuration Management tool? Can you please provide the complete details about that or point me to any web portal which contains details except puppetlabs.com
CODE PROMOTION MODEL
Hi ,
I am looking for a code promotional model example like how to dev-> qa -> uat _ release.
How to maintain the branches ?
How to merge the code after the release if the fixes are there?
Can some give a real time example how it is maintained in other companies.
CM BEST PRACTICES WEB SITE:
www.cmbestpractices.com/
SAMPLE RESUME
Can any attache sample resume for build and release engineer.
I need for reference , not for projects but for technical data.
AUTOMATICALLY BCC ALL OUTGOING MESSAGES
automatically Bcc all outgoing messages
www.outlookcode.com/article.aspx?id=72
IBM RATIONAL CLEARCASE VERSION 7.1.1 RELEASE
TEST TOPICS
test topics
AFTER 9 YRS……………..
Hi Everyone,
If ur working as a build and release engineer what would be the growth or opportunity after 9 yrs.
Various path :
1) Can we become a release manger (do we have more opportunity )
2) Is there any certification for becoming release manager
To be clear if we work as developer or QA or System Engineer we may become architect or manager or may be any thing which have opportunity .
want clear way for build and release engineer
CANNOT OPEN THE DISK
Earlier my disk was full and my VMware stopped working.
Later when i start my VM after disk cleanup, i am getting following error. any idea?
Cannot open the disk ‘C:\Windows XP Professional-000002.vmdk’ or one of the snapshot disks it depends on.
Reason: The specified virtual disk needs repair.
BEST PRACTICE IN BRANCHING
Git does not dictate a process, so usually each project does. Common featurs:
–> Branch for features
–> Branch for fixes
–> Branch for experiments
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
SHELL OR PERL
When do we use the shell or perl scripting in build or configuration mgnt?
Any example?
Which can be preferd shell or perl for build and release carrer?
HOW TO HIRE THE BEST WEBSITE DESIGN COMPANY.
Once a business has been developed and set up properly, the need for a website arises. The website is the online identity of a company and it is necessary that you hire an experienced and professional website design company who can complete the task perfectly. While looking for the best website design company you should compare the prices as well as services offered by the various companies in the market. Before hiring a website design company, it is necessary to assemble the various ideas or thoughts of what your business needs and requirements are. Even if you have already hired a web designer, you still need your website to project your ideas. Creating a list of ideas and services that you plan to offer through your site is a good idea so that when you hire the design company, you are already prepared.
You should also make sure that the company you hire has a good track record in terms of customer satisfaction. This can be done by asking your friends who have utilized the firm’s services or by reading customer reviews online. Checking out their work portfolio can give you a better view of their work quality and their individual style. You can choose the services of a firm depending on whether or not the services offered meet your requirements and specifications and whether that design company has the ability and talent required to design your website you are thinking of.
COMPONENT OBSOLESCENCE TRACKING
Often obsolescence management is confined to availability of parts, but the issue of obsolescence management goes beyond. There are key issues related to it- design for the longest possible product life cycle, availability of electronic parts, skills to modify the product, product knowledge, system and domain, tools to modify the product and continuing Electronic Security and Support Issues. While the product is being designed it is important to identify the parts that pose the greatest obsolescence risk. Component Obsolescence Management has to be balanced against product features.
For example, opto-electronic displays (LCDs, OLEDs) commonly tend to become obsolete quickly despite big promises made by their vendors. The design phase will result in a list of parts that are at risk for obsolescence. A proactive approach must be taken to manage these at risk parts. This is possible only if the product is part of an expensive long life cycle product. An estimate is prepared for the requirement of at risk parts for the entire life cycle and these parts are procured. This is a costly process and it is important to correctly identify the risk parts and limit the procurement to them. It is also important to store the parts acquired properly. A less costly approach for handling at risk components is to do obsolescence tracking for them. For critical components, it is essential that the availability be proactively checked every month. Thus, you will want to buy enough components to make sure your product stays in production while your engineering team redesigns the product to not use the part about to go obsolete.
APPLICATION PACKAGING INTERVIEW TIPS…….
Hi,
Need advise for preparation of application packaging interview .
Currently i am working on Installshield.
What are the general questions do we expect for application packaging job ?
BUILD AND RELEASE ENGINEER JOB GROWTH ?
Hi guys,
I am working on build and release from past 1.5 years (70%) on installshield cruisecontrol,maven,finalbuilder,hudson on windows platform.
Apart form these i am working on .net (bug fixing).
I am in a confusion whether to change my designation to build and release engineer or software engineer.
How will be growth in build and release ?
UNIX COMMAND
Hi All,
What is the command to find error line in a file and 10 lines above abd 10 lines below error line?
Say if I have a error text at line 35, I want 10 lines above 35th line and below 10 lines below 35th line.
EC2 FTP CONNECTION PROBLEM – WINDOWS INSTANCE –
We’re trying ftp connection from EC2 ftp client to external our server.
But we encounterd the following ftp connection problem.
We need to solve this problem.
We are very much appreciated if you could give us the solutions.
1. Problem
EC2 ftp client fail to conect to ftp Server ,
pwd or cd command can work, but ls, put and get comand cannot work.
We need to use Windows ftp command for connection.
ftp client is EC2 and have Elastic IP address
ftp server is on our office side and have grobal IP address.
2. ftp client Environment
Amazon EC2
Windows 2003 Server Instance
Windows ftp command
EC2 Elastic IP address – zz.zz.zz.zz
EC2 Internal IP address – aa.aa.aa.aa
We used EC2 as ftp client, not ftp server.
3. ftp Server Environment
ftp server is on our office Japan.
it have a grobal IP address xx.xx.xx.xx.
4. firewall security on our office
Our office -> EC2(internet) : all tcp permitted
EC2(internet) -> Our office: tcp20/21 permitted.
5. EC2 security group setting.
tcp20/21 from any IP permitted
6. EC2 ftp client Log
ftp> open xx.xx.xx.xx
Connected to xx.xx.xx.xx
220 ftp server ready.
User (xx.xx.xx.xx:(none)):
—> USER yyyyy
331 Password.
—> PASS ecopass
230 User yyyyy logged in super!
ftp> cd LogFiles\DayLog
—> CWD LogFiles\DayLog
250 CWD command succesful.
ftp> ls
—> PORT aa,aa,aa,aa,9,134
200 PORT command successful.
—> NLST
150 ASCII data.
xx.xx.xx.xx means that ftp Server grobal IP address
aa,aa,aa,aa means that EC2 Internal IP address
7. ftp Server ftp log
Session 7, Peer xx.xx.xx.xx ftp Server session started
Session 7, Peer xx.xx.xx.xx ftp Server session started
Session 7, Peer xx.xx.xx.xx USER xxxx
Session 7, Peer xx.xx.xx.xx 331 User name ok, need password
Session 7, Peer xx.xx.xx.xx ftp: Login attempt by: xxxx
Session 7, Peer xx.xx.xx.xx PASS XXXXXXX
Session 7, Peer xx.xx.xx.xx 230 User logged in
Session 7, Peer xx.xx.xx.xx ftp: Login successful
Session 7, Peer xx.xx.xx.xx PORT aa,aa,aa,aa ,5,106 <- EC2 Internal IP Address
Session 7, Peer xx.xx.xx.xx 200 PORT command successful.
Session 7, Peer xx.xx.xx.xx NLST
Session 7, Peer xx.xx.xx.xx Could not connect to peer. Aborting transfer.
Session 7, Peer xx.xx.xx.xx 226 Closing data connection
Session 7, Peer xx.xx.xx.xx QUIT
Session 7, Peer xx.xx.xx.xx 221 Service closing control connection
Session 7, Peer xx.xx.xx.xx ftp: Connection closed.
8. reason why
It seems that EC2 Internal IP address is used when ftp Server tried to
tansfer data to EC2 ftp client by TCP20.
We tried ftp PASSIVE mode by literal command, but rejected by ftp Server.
ftp> literal pasv
—> pasv
502 [pasv] Command not implemented.
W need to solve this problem.
Thank you for reading.
Message was edited by: mgcloud
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
DIRECTLY SUPPORTED BUILD TOOLS
Shell / command script
Ant
Groovy
OpenMake Meister
Maven
Maven2
Make
MsBuild
NAnt
Rake (Ruby)
Visual Studio (‘devenv’)
FinalBuilder
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
LIST OF TEST TOOLS
Agitar
CppUnit result rendering
JUnit result rendering
NUnit result rendering
QualityCenter test rendering
PHPUnit result rendering
PMD result rendering
Clover result rendering
Selenium result rendering
SilkCentral
MSTest result rendering
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
LIST OF ISSUE & PM INTEGRATIONS
Bugzilla
ClearQuest
Confluence
JIRA
Mingle
QualityCenter
Rally
Rubyforge.org
Scarab
Sourceforge.net
Trac
VersionOne
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
LIST OF SCM TOOLS
List of SCM Tools (Version Control Tools / Configuration Management Tools)
AccuRev
AlienBrain
Bazaar
BitKeeper
ClearCase
CA Harvest
CM Synergy
CVS
Dimensions
File system SCM
Git
HTTP file
MKS
Perforce (p4)
PVCS
SourceGear Vault
StarTeam
Subversion
Surround
Team Foundation Server
VSS
VSS Journal
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
QUESTION FROM RELEASE ENGINEER SCM PERSPECTIVE
1. How many major, minor releases a year per project?
2. How many customers per release per project?
3. How do you deliver the releases to the customers? – Is it physical media
4. distribution or Push/Pull mechanism from web or any other process?
5. Is the distribution CD/DVD creation process automated?
6. What is the size of the release deliverable?
7. What are the contents of a release?
8. How is the release bundle tested?
9. How many platforms are certified? How different are the release packages?
10. Is there any release check-list for cross-check?
11. Is any part of the release process automated?
12. Is there a need for i18n? If yes, is the i18n release handled separately?
13. In case of installers, is there installer testing? Is it automated?
14. Is the release schedule well-planned?
15. Are you delivering patches in well constructed and cost effective way?
16. Is there any release audit process in place?
17. How are you tracking your releases?
18. Is there any legal compliance in place while shipping the release to the customers?
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
QUESTION FROM BUILD ENGINEER SCM PERSPECTIVE
1. What is the build process adopted (automated/manual)?
2. Are there nightly builds?
3. Is there continuous integration?
4. Are there smoke and sanity tests at the end of the build?
5. What is the build acceptance criterion (BAT)?
6. What is the build duration? Is it optimal?
7. How are pre-conditions to the build verified?
8. Are there any build environment integrated automated unit test-cases?
9. Is there any enforcement tool on coding standards?
10. Is there any code coverage tool being used?
11. Are the post build activities automated?
12. Any additional practices (like checksum generation, signing the build artifacts) in place as part of the build?
13. Are there any scripting technologies used in automating build process?
14. Is Labeling strategy well-defined?
15. If any third party tool is being used for packaging, is that package creation process automated?
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
QUESTION FROM CONFIGURATION MANAGER SCM PERSPECTIVE
1. Do you know what files/documents should be delivered?
2. How do you track who changed what, when, where, and why?
3. How long does a build or release take?
4. Is there a Configuration Management Plan document?
5. Is there a tight integration between Version control tool and Bug/Change tracking tool?
6. How the parallel (if any) development is enabled? Any limitations with the current branching strategy?
7. Is this project development spanned across multiple sites? If so, what is your multi-site strategy?
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
QUESTION FROM TESTERS SCM PERSPECTIVE
1. Do you know what files/documents should be delivered?
2. How do you assess, and track the impact of a proposed change?
3. Can you show me what artifact versions went into a certain release?
4. How comfortable are you working with Bug/Change management tool?
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
QUESTIONS FROM DEVELOPERS IN SCM PERSPECTIVE
1. How do you baseline project artifacts?
2. Can you build your system reliably and repeatedly?
3. Explain your labeling scheme?
4. Can you show me what versions went into a certain release?
5. What does the version tree for this file look like?
6. How many product versions are you supporting at the moment?
7. What is the version control tool being used? Is it user friendly?
8. What is the bug tracking/change management tool being used? Is it user friendly?
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
QUESTION FROM PROJECT/DEVELOPMENT MANAGERS SCM PERSPECTIVE
How do you maintain all the artifacts together and version them?
Where are the people working on the project located?
What’s the difference between Developer CM and Release CM?
How do you assess, and track the impact of a proposed change?
How do you manage system integration of modules developed by individual developers?
How many product versions are you supporting at this moment?
Who is the designated Configuration Manager?
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
QUESTIONS TO IDENTIFY THE SUPPORTING TOOLS
What are the tools that you currently use in your work?
How is the integration among the above tools?
Are we using the tool features the way they are designed or intended?
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
QUESTIONS TO CHARACTERIZE THE PROJECT APPLICATION
- What is the size of each project (duration, persons, person years, LOC)
- What type (maintenance / enhancement / new development / prototype / feasibility)
- What type of development model is being used?
- Are we using any process models like UCM, RUP or any other?
- Any industry/domain specific standards (like CMMI, ITIL etc.) to be followed?
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
MIGRATION OF CLEARCASE TO GIT
Could anyone help me in this case, migrating CC vob to GIT.
Thanks & Regards,
Vijay
LOOKING FOR SUGGESTIONS FOR BUILD JOBS
Looking for suggestions for build jobs using Mercurial MQ
Hello
I’ve recently setup matrix projects to test Py libs (so far axis are
the version of the interpreter and versions of dependencies) .
Considering the fact that Hudson Mercurial plugin doesn’t provide
explicit support for MQ (AFAIK) I’m looking for suggestions so as to
find ways to work around this limitation in order to achieve the
following
1. First of all I’d like to test each and every revision
committed to the repository . I think this could be
achieved by parameterizing the build job and
supplying individual revision number
to the build in the Hg hook that triggers it
from remote (is there a better way to do this ?)
2. I’d like to start a variable number of jobs , more
precisely one job for each patch in the queue .
The goal is to ensure that every patch will work
if applied against repository trunk (have
no idea of how to do this …)
3. I need to copy some (script) files to the workspace
before starting the build (and I don’t use neither Ant
nor Maven, nor MSBuild, nor … I just need to copy
static files ;o) .
4. I need to publish in the build results page
some files generated
during the build (binaries, logs, … ) and browse
(some of) them inside Hudson site . They should
be accessible from the page showing build results
e.g. myserver.com/job/jobname/49
(I suppose this is the «Archive the artifacts» +
«Files to archive» combination … isn’t it ? )
5. I need to execute custom scripts only if the build
succeds.
Please ideas and suggestions about how to do this (and probably
plugins that need to be installed, …) will be very welcomed.
Thnx in advance !
FINDING COMPUTER NAME USING IP
I need to find the computer name of one PC connected in LAN (joined to domain).
I have the IP address of terminal. how i will find the computername?
kindly advice
Regards,
Rajesh Kumar
Twitt me @ twitter.com/RajeshKumarIn
ARTICLE FORMATTING
Where can I find the help for formatting the articles? Like syntax for adding code, images, url etc.
Thanks,
-Tushar
UNPUBLISHED ARTICLES
I have posted 2 articles but looks like not published yet.
Please let me know if these requires any modifications.
HOW TO LESSEN DEPLOYMENT TIME?
Hi All,
Can anyone please let me know any technique in which we can reduce the deployment time from Dev environment to other environment, we currently use robocopy for copying files.
Please share your ideas/ suggestions.
A FORUM TO DISCUSS APPLICATION PACKAGING
A Forum to discuss Application packaging related issues, troubleshoot, queries, tools and share knowledge. Covers all installer software.
www.packaginggalaxy.com
www.packaginggalaxy.com – A Forum to discuss Application packaging related issues, troubleshoot, queries, tools and share knowledge. Covers all installer software such as
wyBuild & wyUpdate
WiX
Wise Package Studio
Wise Installation Express 7
Wise Installation Studio 7
Windows Installer
VISE X
Tarma QuickInstall 2
Tarma Installer 5
Tarma ExpertInstall 3
Smart Install Maker
Setup Factory
SetupBuilder Professional Edition
Scriptlogic Desktop Authority MSI Studio
Scriptlogic Desktop Authority MSI Studio
Remote Install Mac OS X
QSetup
Nullsoft Scriptable Install System (NSIS)
MSI Package Builder
LANrev InstallEase
JExpress
Instyler Setup
Installer VISE
InstallShield
InstallAnywhere
InstallAce
Install Creator (Pro)
InstallBuilder
InstallAware
Inno Setup
Iceberg
Excelsior Delivery
Excelsior Installer
DreamShield
DeployMaster
CreateInstall Free
CreateInstall Light
CreateInstall
ClickInstall
Advanced Installer
Tagged : git / puppet