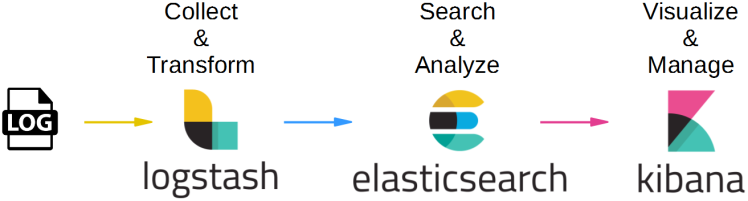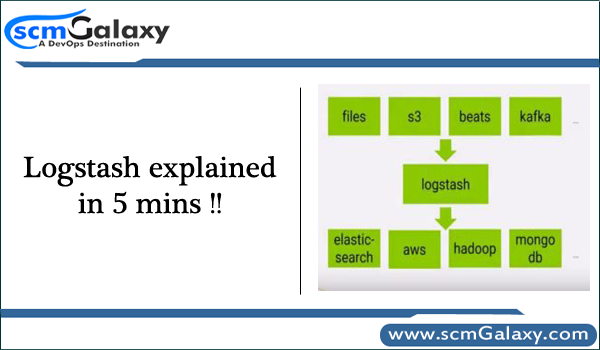
What is Logstash?
Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your favorite “stash.”
Logstash Benefits
- Logstash allows you to easily ingest unstructured data from a variety of data sources including system logs, website logs, and application server logs.
- Logstash offers pre-built filters, so you can readily transform common data types, index them in Elasticsearch, and start querying without having to build custom data transformation pipelines.
- With over 200 plugins already available on Github, it is likely that someone has already built the plugin you need to customize your data pipeline.
Logstash work in 3 phases….
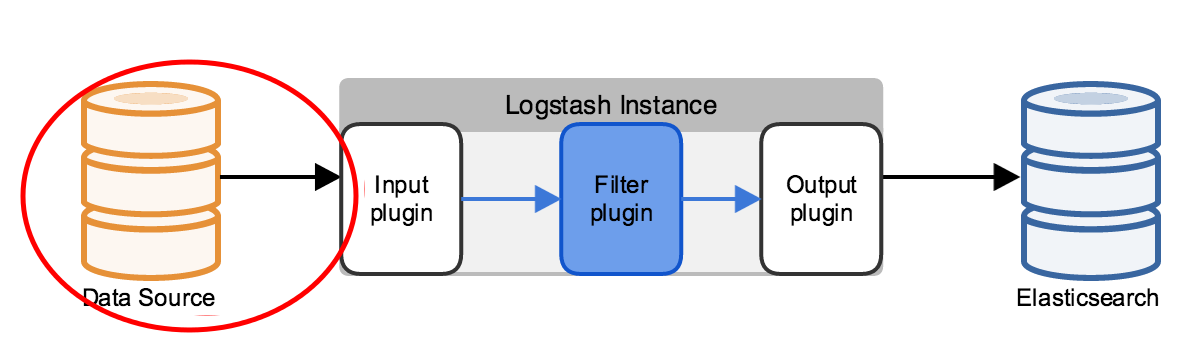
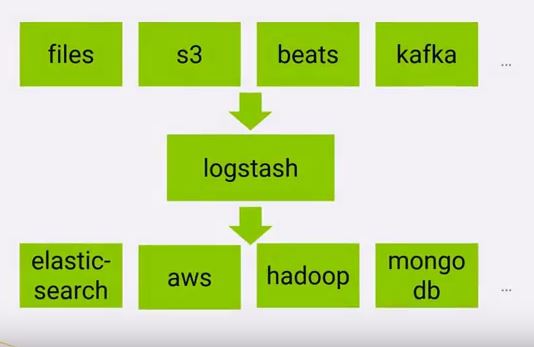
Phase 1 – When it comes from ingests data from a multitude of sources simultaneously, which includes files, s3,beats, kafka etc. Data is often scattered or siloed across many systems in many formats. Logstash supports a variety of inputs that pull in events from a multitude of common sources, all at the same time.
List of sources from where logstash can ingest the data are as follows;
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
Phase 2 – Next, It Parse & Transform Your Data On the Fly. As data travels from source to store, Logstash filters parse each event, identify named fields to build structure, and transform them to converge on a common format for easier, accelerated analysis and business value. Logstash dynamically transforms and prepare your data regardless of format or complexity
Phase 3 – Last, Logstash stored the parsed data into Elasticsearch, aws,hadoop, Mongodb and go-to output that opens up a world of search and analytics possibilities.Logstash has a variety of outputs that let you route data where you want, giving you the flexibility to unlock a slew of downstream use cases. Some of these are given below;
https://www.elastic.co/guide/en/logstash/current/output-plugins.html
Where you can use the Logstash?
- Log Analytics – Ingest un-structured and semi-structured logs generated by servers, applications, mobile devices, and more for a wide variety of applications such as digital marketing, application monitoring, fraud detection, ad tech, gaming, and IoT. Logstash provides plugins to quickly load data from a variety of data sources.
- IT Operations Monitoring – Capture server logs and push them into your Elasticsearch cluster using Logstash. Elasticsearch indexes the data and makes it available for analysis in near real-time (less than one second). You can then use Kibana to visualize the data and perform operational analyses like identifying network issues and disk I/O problems. Your on-call teams can perform statistical aggregations to identify root cause and fix issues.