Graphical Models Libraries are software tools or frameworks that provide functionality for constructing, analyzing, and performing inference in graphical models. Graphical models, also known as probabilistic graphical models, are statistical models that represent the probabilistic relationships between a set of variables using a graph structure.
Here are the 10 top graphical models libraries:
1. Pyro:
Pyro is a flexible probabilistic programming library developed by Uber AI. It provides a unified framework for building deep probabilistic models and performing Bayesian inference. Pyro supports a variety of modeling techniques, including directed and undirected graphical models, and offers tools for variational inference and Monte Carlo methods.
2. Edward:
Edward is a probabilistic programming library built on top of TensorFlow. It focuses on Bayesian modeling and inference, making it easy to specify and train complex probabilistic models. Edward supports both directed and undirected graphical models and provides algorithms for approximate inference.
3. Stan:
Stan is a popular probabilistic programming language that supports modeling and inference for graphical models. It offers a powerful modeling language and provides efficient algorithms for Bayesian inference, including Hamiltonian Monte Carlo (HMC). Stan has interfaces for various programming languages, such as Python, R, and MATLAB.
4. PyMC3:
PyMC3 is a Python library for probabilistic programming that specializes in Bayesian modeling and inference. It supports both directed and undirected graphical models and provides a wide range of inference algorithms, including Markov chain Monte Carlo (MCMC) methods. PyMC3 integrates well with NumPy and TensorFlow.
5. Infer.NET:
Infer.NET is a popular open-source framework developed by Microsoft Research. It supports the modeling and inference of graphical models, including both directed and undirected models. Infer.NET offers a rich set of modeling constructs and efficient inference algorithms, making it suitable for a wide range of applications.
6. OpenGM:
OpenGM is a C++ library for graphical models that supports various types of graphical models, including factor graphs and Markov random fields. It provides a flexible interface for constructing and manipulating graphical models and offers efficient algorithms for inference and optimization.
7. pomegranate:
pomegranate is a Python library that focuses on probabilistic modeling and inference, including graphical models. It supports both directed and undirected graphical models and provides a range of algorithms for learning and inference, such as belief propagation and Viterbi decoding.
8. Graph-tool:
Graph-tool is a Python library for working with graph structures and performing graph-based computations. It includes functionality for building and analyzing graphical models, including factor graphs and Markov random fields. Graph-tool provides efficient algorithms for inference and optimization.
9. Libra:
Libra is a C++ library for graphical models that supports both directed and undirected graphical models. It offers a wide range of inference algorithms, including variational methods and message passing algorithms. Libra also provides tools for learning the structure and parameters of graphical models.
10. HUGIN:
HUGIN is a comprehensive suite of tools for probabilistic graphical modeling. It includes a graphical modeling language and supports both directed and undirected graphical models. HUGIN provides algorithms for exact and approximate inference, parameter learning, and structure learning.
Machine Learning, ML for short, is an area of computational science that deals with the analysis and interpretation of patterns and structures in large volumes of data. Through it, we can infer insightful patterns from data sets to support business decision-making – without or with very little need for human interface.
In Machine Learning, we feed large volumes of data to a computer algorithm that then trains on it, analyzing it to find patterns and generating data-driven decisions and recommendations. If there are any errors or outliers in information identified, the algorithm is structured to take this new information as input to improve its future output for recommendations and decision-making.
Simply put, ML is a field in AI that supports organizations to analyze data, learn, and adapt on an ongoing basis to help in decision-making. It’s also worth noting that deep learning is a subset of machine learning.
What is a Machine Learning Framework?
A simplified definition would describe machine learning frameworks as tools or libraries that allow developers to easily build ML models or Machine Learning applications, without having to get into the nuts and bolts of the base or core algorithms. It provides more of an end-to-end pipeline for machine learning development.
Here are the top 20 machine learning frameworks:
TensorFlow
PyTorch
scikit-learn
Keras
MXNet
Caffe
Theano
Microsoft Cognitive Toolkit (CNTK)
Spark MLlib
H2O.ai
LightGBM
XGBoost
CatBoost
Fast.ai
Torch
CNTK (Microsoft Cognitive Toolkit)
Deeplearning4j
Mahout
Accord.NET
Shogun
1. TensorFlow:
Developed by Google’s Brain Team, TensorFlow is one of the most widely used machine learning frameworks. It provides a comprehensive ecosystem for building and deploying machine learning models, including support for deep learning. TensorFlow offers high-level APIs for ease of use and low-level APIs for customization.
Key Features:
Based on JavaScript
Open source and has extensive APIs
Can be used via script tags or via installation through npm
Runs on CPUs and GPUs
Extremely popular and has lots of community support
2. PyTorch:
PyTorch is a popular open-source machine learning framework developed by Facebook’s AI Research Lab. It has gained significant popularity due to its dynamic computational graph, which enables more flexibility during model development. PyTorch is widely used for research purposes and supports both deep learning and traditional machine learning models.
Key Features:
Supports cloud-based software development
Suitable for designing neural networks and Natural Language Processing
Used by Meta and IBM
Good for designing computational graphs
Compatible with Numba and Cython
3. scikit-learn:
scikit-learn is a Python library that provides a simple and efficient set of tools for data mining and machine learning. It offers a wide range of algorithms for classification, regression, clustering, and dimensionality reduction. scikit-learn is known for its user-friendly API and extensive documentation.
Key Features:
Works well with Python
The top framework for data mining and data analysis
Open-source and free
4. Keras:
Keras is a high-level neural networks API written in Python. Initially developed as a user-friendly interface for building deep learning models on top of TensorFlow, Keras has evolved into an independent framework. It provides an intuitive and modular approach to building neural networks and supports both convolutional and recurrent networks.
5. MXNet:
MXNet is a deep learning framework that emphasizes efficiency, scalability, and flexibility. It offers both imperative and symbolic programming interfaces, allowing developers to choose the approach that best suits their needs. MXNet is known for its support of distributed training, which enables training models on multiple GPUs or across multiple machines.
Key Features:
Adopted by Amazon for AWS
Supports multiple languages, including Python, JavaScript, Julia, C++, Scala, and Perl
Microsoft, Intel, and Baidu also support Apache MXNet
Also used by the University of Washington and MIT
6. Caffe:
Keeping speed, modularity, and articulation in mind, Berkeley Vision and Learning Center (BVLC) and community contributors came up with Caffe, a Deep Learning framework. Its speed makes it ideal for research experiments and production edge deployment. It comes with a BSD-authorized C++ library with a Python interface, and users can switch between CPU and GPU. Google’s DeepDream implements Caffe. However, Caffe is observed to have a steep learning curve, and it is also difficult to implement new layers with Caffe.
7. Theano:
Theano was developed at the LISA lab and was released under a BSD license as a Python library that rivals the speed of the hand-crafted implementations of C. Theano is especially good with multidimensional arrays and lets users optimize mathematical performances, mostly in Deep Learning with efficient Machine Learning Algorithms. Theano uses GPUs and carries out symbolic differentiation efficiently.
Several popular packages, such as Keras and TensorFlow, are based on Theano. Unfortunately, Theano is now effectively discontinued but is still considered a good resource in ML.
8. Microsoft Cognitive Toolkit (CNTK):
CNTK is a deep learning framework developed by Microsoft. It provides high-level abstractions and supports both convolutional and recurrent neural networks. CNTK is known for its scalability and performance, particularly in distributed training scenarios.
9. Spark MLlib :
Spark MLlib is a machine learning library provided by Apache Spark, an open-source big data processing framework. Spark MLlib offers a wide range of tools and algorithms for building scalable and distributed machine learning models. It is designed to work seamlessly with the Spark framework, enabling efficient processing of large-scale datasets.
10. H2O.ai :
H2O.ai is an open-source machine-learning platform that provides a range of tools and frameworks for building and deploying machine-learning models. It aims to make it easy for data scientists and developers to work with large-scale data and build robust machine-learning pipelines.
11. LightGBM:
LightGBM is an open-source gradient-boosting framework developed by Microsoft. It is specifically designed to be efficient, scalable, and accurate, making it a popular choice for various machine-learning tasks.
12. XGBoost:
XGBoost (Extreme Gradient Boosting) is a powerful and widely used open-source gradient boosting framework that has gained significant popularity in the machine learning community. It is designed to be efficient, scalable, and highly accurate for a variety of machine-learning tasks.
13. CatBoost:
CatBoost is an open-source gradient-boosting framework developed by Yandex, a Russian technology company. It is specifically designed to handle categorical features in machine learning tasks, making it a powerful tool for working with structured data.
14. Fast.ai:
Fast.ai is a comprehensive deep-learning library and educational platform that aims to democratize and simplify the process of building and training neural networks. It provides a high-level API on top of popular deep learning frameworks like PyTorch, allowing users to quickly prototype and iterate on their models.
15. Torch:
Torch, or PyTorch, is a widely used open-source deep learning framework that provides a flexible and efficient platform for building and training neural networks. It is developed and maintained by Facebook’s AI Research Lab (FAIR).
16. CNTK (Microsoft Cognitive Toolkit):
CNTK (Microsoft Cognitive Toolkit), now known as Microsoft Machine Learning for Apache Spark, is an open-source deep learning framework developed by Microsoft. It provides a flexible and scalable platform for building, training, and deploying deep learning models.
17. Deeplearning4j:
Deeplearning4j (DL4J) is an open-source deep-learning library specifically designed for Java and the Java Virtual Machine (JVM) ecosystem. It provides a comprehensive set of tools and capabilities for building and training deep neural networks in Java, while also supporting integration with other JVM-based languages like Scala and Kotlin.
18. Mahout:
Apache Mahout is an open-source machine learning library and framework designed to provide scalable and distributed implementations of various machine learning algorithms. It is part of the Apache Software Foundation and is built on top of Apache Hadoop and Apache Spark, making it well-suited for big data processing.
19. Accord.NET:
Accord.NET is an open-source machine learning framework for .NET developers. It provides a wide range of libraries and algorithms for various machine-learning tasks, including classification, regression, clustering, neural networks, image processing, and more. Accord.NET aims to make machine learning accessible and easy to use within the .NET ecosystem.
20. Shogun:
Shogun is an open-source machine-learning library that provides a comprehensive set of algorithms and tools for a wide range of machine-learning tasks. It is implemented in C++ and offers interfaces for several programming languages, including Python, Java, Octave, and MATLAB.
Software Development Life Cycle (SDLC) may be a method employed by the software industry to style, develop and check high-quality software. The SDLC aims to supply high-quality software that meets or exceeds client expectations, reaches completion among times and price estimates.
SDLC is that the acronym of Software Development Life Cycle.
It is conjointly referred to as the software development method.
SDLC may be a framework process task performed at every step within the software development method.
ISO/IEC 12207 is a world quality software life-cycle process. It aims to be the quality that defines all the tasks needed for developing and maintaining software.
What is Software Development Lifecycle (SDLC)?
The software Development Life Cycle (SDLC) could be a structured method that permits the assembly of high-quality, low-priced software, within the shortest attainable production time. The goal of the SDLC is to provide superior software that meets and exceeds all client expectations and demands.
SDLC may be a method followed for a software project, inside a software organization. It consists of an in-depth setup describing the way to develop, maintain, replace and alter or enhance specific software. The life cycle defines a strategy for improving the standard of software and also the overall development method.
Why SDLC is important for developing a software system?
SDLC permits developers to research the necessities. It helps in reducing unnecessary prices throughout development. It allows developers to style and builds high-quality software products. This can be as a result of them following a scientific method that permits them to check the software before it’s extended.
Forms the foundation for project planning and scheduling
Helps estimate cost and time
Includes the project activities and deliverables of each phase
Boosts the transparency of the entire project and the development process
Enhance the speed and accuracy of development
Minimizes the risk potential and maintenance during any given project
Its defined standard improves client relations
What are the Benefits of the Software Development Lifecycle?
It makes it clear what the problem or goal is. It is easy to get ahead of yourself when taking on a large project. With the SDLC you can clearly see the goals and the problems so that the plan is implemented with precision and relevance.
The project is designed with clarity. Project members cannot move from one stage to another until the prior stage is completed and signed off on by the project manager. A formal review is created at the end of each stage, which allows the project manager to have maximum management control.
It will be properly tested before being installed. The installation in a project that is executed using an SDLC has the necessary checks and balances so that it will be tested with precision before entering the installation stage.
If a key project member leaves, a new member can pick up where they left off. The SDLC gives you a well-structured and well-documented paper trail of the entire project that is complete with records of everything that occurs.
Without the SDLC, the loss of a project member will set you back and probably ruin the project. If paperwork is missing or incomplete, the new project member can have to be compelled to begin from the start and even probably amendment the project to create sense of it. With a well-designed SDLC, everything is so as in order that a replacement project member will continue the method while not complications.
The project manager will properly manage a project if deliverables are completed on time and among the budget. sticking to a budget is simpler with a well-organized arrange during which you’ll see all the timetables and prices. Project members will submit their work to an integrated system that flags something that’s past due. Once the project manager will pay less time micromanaging, he or she will be able to pay longer improving potency and production.
The project can continuously loop around until it is perfect. The stages are meant to feed back into the earlier stages, so the SDLC model provides the project with flexibility.
When designing and implementing a project, a software development life cycle is the solution. It’s the best way to ensure optimal control, minimize problems, and allow the project manager to run production without having to micromanage the project members.
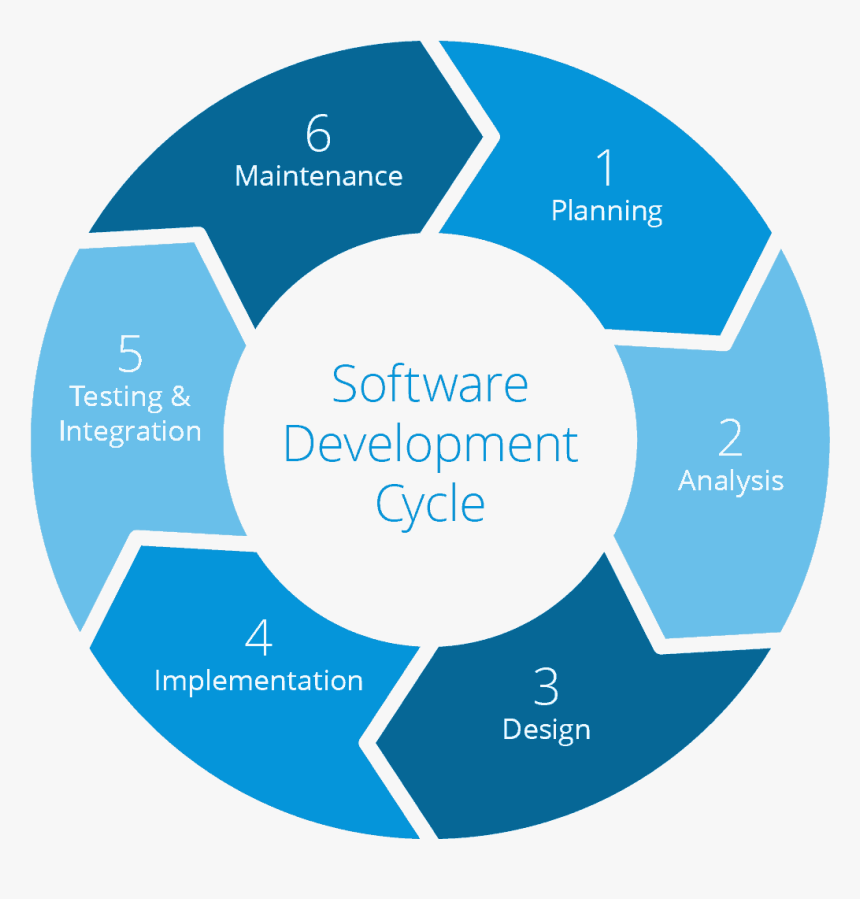
Stages of the SDLC:
Every software development company goes through an array of stages as they embark on a systematic process of development. From planning to design and development, here is a brief glance at the six essential stages of SDLC required to create flawless software:
Planning
Without a clear, visionary plan in place, it is difficult to align everything with your project goals and judge all its strengths, scope, and challenges involved.
The planning is to ensure the development goes easy and smooth, meets its purpose, and achieves its desired progress within the given time limit.
Analysis
Analyzing the requirements and performance of the software through its multiple stages is key to deriving process efficiency.
Analysis always helps be in the know of where you exactly stand in the process and where you need to be and what it takes to pass through the next step down the path.
Design
After the analytical part is complete, the design is the next step that needs to look forward to. The basic aim in this phase is to create a strong, viable architecture of the software process.
As it works by standard adherence, it helps eliminate any flaws or errors that may possibly hinder the operation.
Development
Once the design is ready, the development takes over along with efficient data management and recording. This is a complicated phase where clarity and focus are of great significance.
Post-development, implementation comes into the picture to check whether or not the product functions as expected.
Testing
The testing phase that comes now is inevitable as it studies and examines the software for any errors and bugs that may cause trouble.
Maintenance
If the software has performed well through all the previous five steps, it comes to this final stage called maintenance. The product here is properly maintained and upgraded as and when needed to make it more adaptive to the target market.
How many SDLC models are there?
Today, there are more than 50 recognized SDLC models in use. None of them is perfect, and each brings its favorable aspects and disadvantages for a specific software development project or a team.
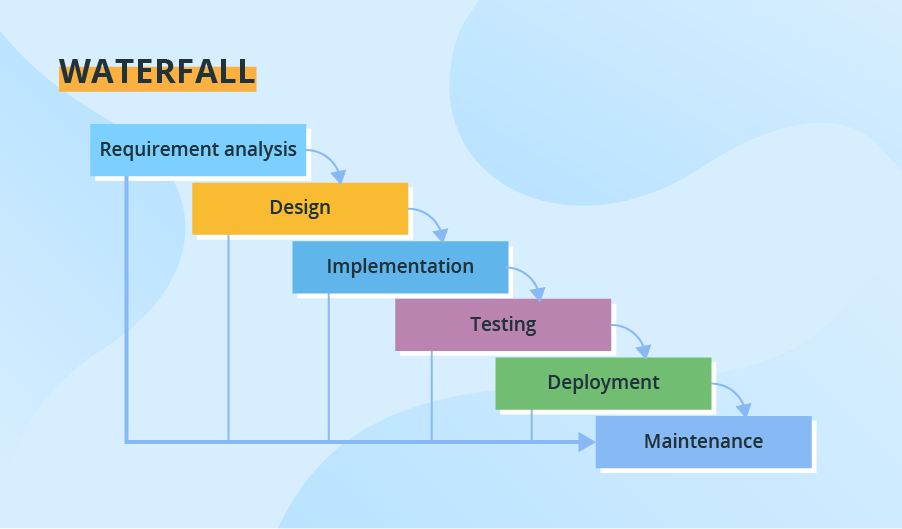
Waterfall
Through all development stages (analysis, design, coding, testing, deployment), the method moves in a very cascade model. Every stage has concrete deliverables and is strictly documented. The consecutive stage cannot begin before the previous one is totally completed. Thus, as an example, software needs cannot be re-evaluated any in development. There’s additionally no ability to check and take a look at the software until the last development stage is finished, which ends up in high project risks and unpredictable project results. Testing is usually rushed, and errors are expensive to repair.
SDLC Waterfall model is used when:
Requirements are stable and not changed frequently.
An application is small.
There is no requirement which is not understood or not very clear.
The environment is stable
The tools and techniques used is stable and is not dynamic
Resources are well trained and are available.
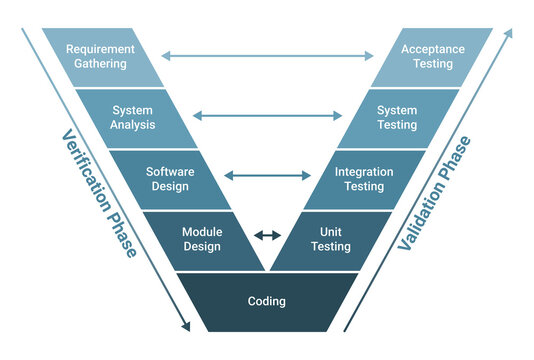
V-model (Validation and Verification model)
The V-model is another linear model with every stage having a corresponding testing activity. Such workflow organization implies exceptional internal control, however, at constant time, it makes the V-model one among the foremost costly and long models. Moreover, although mistakes in needs specifications, code, and design errors will be detected early, changes throughout development are still costly and tough to implement. As within the waterfall case, all needs are gathered at the beginning and can’t be modified.
V model is applicable when:
The requirement is well defined and not ambiguous
Acceptance criteria are well defined.
Project is short to medium in size.
Technology and tools used are not dynamic.
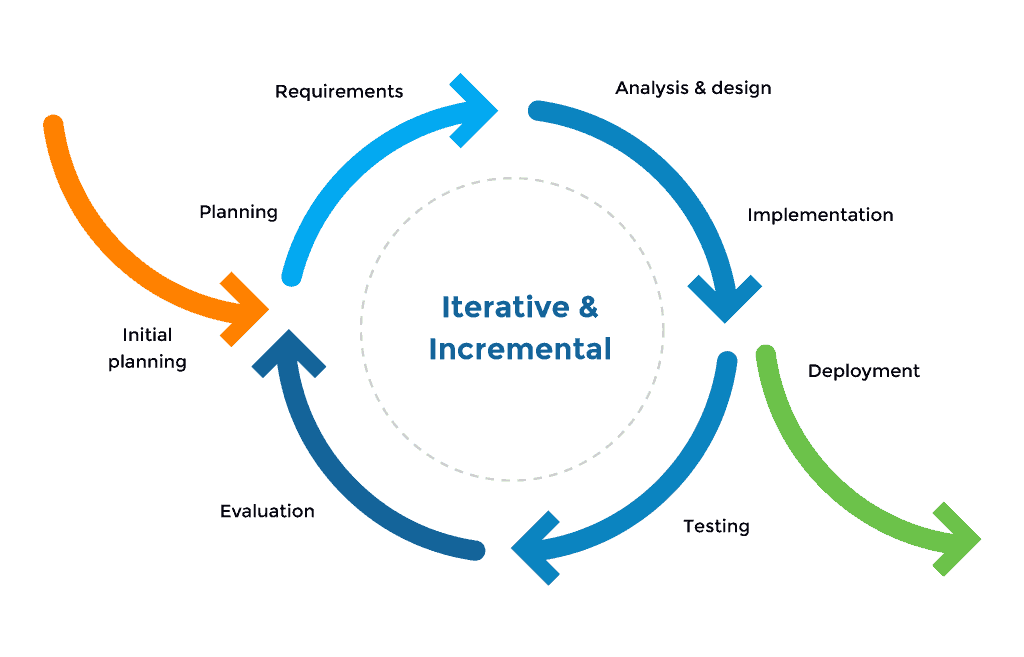
Incremental and Iterative model
Incremental: An incremental approach breaks the software development process down into small, manageable portions known as increments.
Iterative: An iterative model means software development activities are systematically repeated in cycles known as iterations.
Use cases: Large, mission-critical enterprise applications that preferably consist of loosely coupled parts, such as microservices or web services.
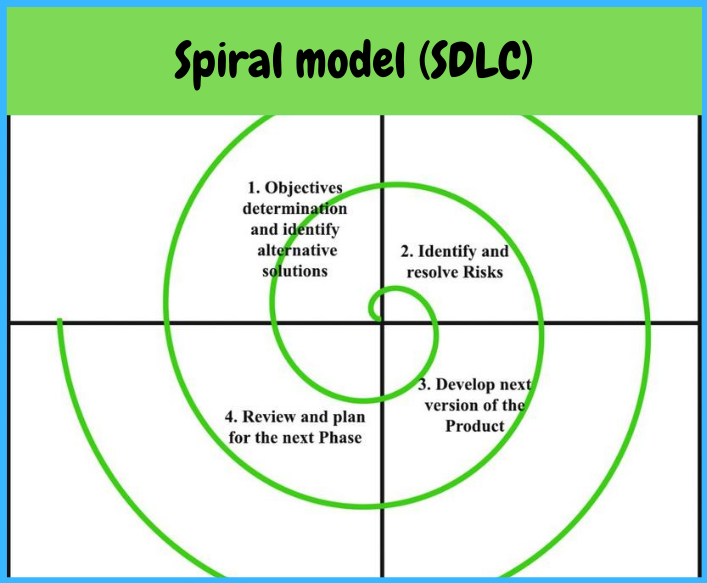
Spiral model
The Spiral model puts concentrates on thorough risk assessment. Thus, to reap the advantages of the model to the fullest, you’ll have to be compelled to have interaction with people with a powerful background in risk evaluation. A typical Spiral iteration lasts around six months and starts with four important activities – thorough designing, risk analysis, prototypes creation, and evaluation of the antecedently delivered part. Continual spiral cycles seriously extend project timeframes.
Uses of the spiral model:
projects in which frequent releases are necessary;
projects in which changes may be required at any time;
long term projects that are not feasible due to altered economic priorities;
medium to high risk projects;
projects in which cost and risk analysis is important;
projects that would benefit from the creation of a prototype; and
projects with unclear or complex requirements.
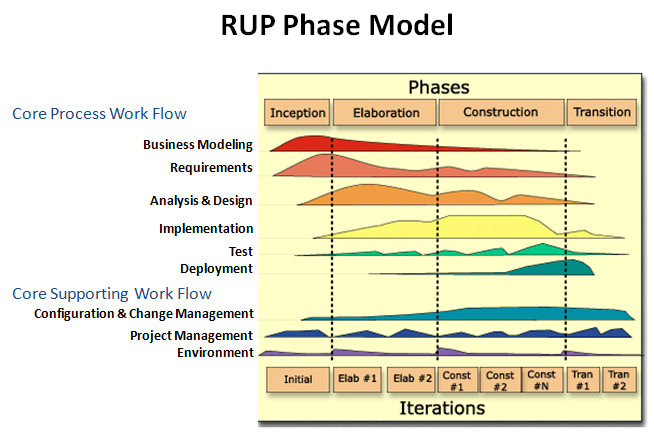
The Rational Unified Process (RUP)
The Rational Unified Process (RUP) is also a mixture of linear and reiterative frameworks. The model divides the software development process into four phases – inception, elaboration, construction, and transition. Every phase however inception is typically done in many iterations. All basic activities (requirements, design, etc) of the development process are done in parallel across these four RUP phases, although with completely different intensities.
RUP helps to make stable and, at a similar time, versatile solutions, but still, this model isn’t as fast and adaptable because of the pure Agile cluster (Scrum, Kanban, XP, etc.). The degree of client involvement, documentation intensity, and iteration length could vary betting on the project wants.
Use cases: Large and high-risk projects, especially, use-case-based development and fast development of high-quality software.
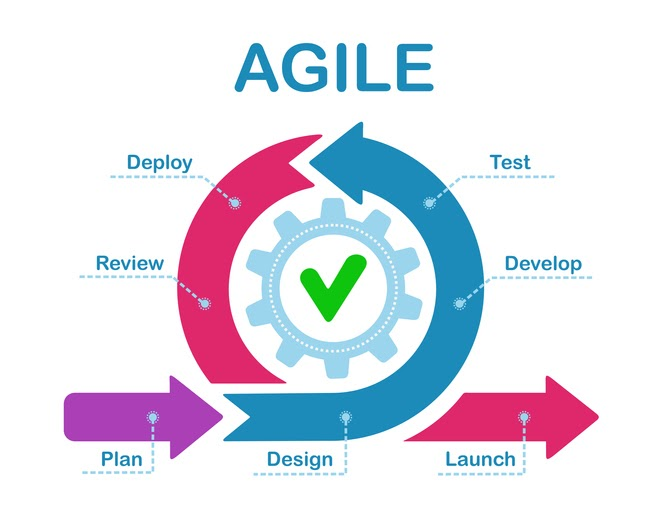
Scrum
Scrum is probably the most popular Agile model. The iterations (‘sprints’) are usually 2-4 weeks long and they are preceded with thorough planning and previous sprint assessment. No changes are allowed after the sprint activities have been defined.
Extreme Programming (XP)
With Extreme Programming (XP), a typical iteration lasts 1-2 weeks. The model permits changes to be introduced even once the iteration’s launch if the team hasn’t begun to work with the relevant software piece yet. Such flexibility considerably complicates the delivery of quality software. To mitigate the matter, XP needs the utilization of try programming, test-driven development and test automation, continuous integration (CI), little releases, easy software style and prescribes to follow the coding standards.
Kanban
As for Kanban, its key distinguishing feature is that the absence of pronounced iterations. If used, they’re unbroken very short (‘daily sprints’). Instead, the emphasis is placed on arranged visualization. The team uses the Kanban Board tool that has a transparent illustration of all project activities, their variety, responsible persons, and progress. Such increased transparency helps to estimate the foremost urgent tasks a lot accurately. Also, the model has no separate strategy planning stage, thus a new modification request will be introduced at any time. Communication with the client is in progress, they’ll check the work results whenever they like, and therefore the meetings with the project team will happen even daily because of its nature, the model is usually employed in projects on software support and evolution.
What are the different phases of the SDLC life cycle?
I have explained all these Software Development Life Cycle Phases
Requirement collection and analysis
The requirement is the first stage in the SDLC process. It is conducted by the senior team members with inputs from all the stakeholders and domain experts in the industry. Planning for the quality assurance requirements and recognization of the risks involved is also done at this stage.
2. Feasibility study
Once the requirement analysis phase is completed the next SDLC step is to define and document software needs. This process was conducted with the help of the ‘Software Requirement Specification’ document also known as the ‘SRS’ document. It includes everything which should be designed and developed during the project life cycle.
3. Design
In this third phase, the system and software design documents are prepared as per the requirement specification document. This helps define the overall system architecture.
This design phase serves as input for the next phase of the model.
There are two kinds of design documents developed in this phase:
High-Level Design (HLD)
Brief description and name of each module
An outline about the functionality of every module
Interface relationship and dependencies between modules
Database tables identified along with their key elements
Complete architecture diagrams along with technology details
Low-Level Design(LLD)
Functional logic of the modules
Database tables, which include type and size
Complete detail of the interface
Addresses all types of dependency issues
Listing of error messages
Complete input and outputs for every module
4. Coding
Once the system design phase is over, the next phase is coding. In this phase, developers start to build the entire system by writing code using the chosen programming language. In the coding phase, tasks are divided into units or modules and assigned to the various developers. It is the longest phase of the Software Development Life Cycle process.
In this phase, the developer needs to follow certain predefined coding guidelines. They also need to use programming tools like compilers, interpreters, debuggers to generate and implement the code.
5. Testing
Once the software is complete, and it is deployed in the testing environment. The testing team starts testing the functionality of the entire system. This is done to verify that the entire application works according to the customer’s requirements.
During this phase, QA and testing team may find some bugs/defects which they communicate to developers. The development team fixes the bug and sends it back to QA for a re-test. This process continues until the software is bug-free, stable, and working according to the business needs of that system.
6.Installation/Deployment
Once the software testing phase is over and no bugs or errors are left in the system then the final deployment process starts. Based on the feedback given by the project manager, the final software is released and checked for deployment issues if any.
7. Maintenance
Once the system is deployed, and customers start using the developed system, the following 3 activities occur
Bug fixing – bugs are reported because of some scenarios which are not tested at all
Upgrade – Upgrading the application to the newer versions of the Software.
Enhancement – Adding some new features into the existing software.
Which SDLC Model is Best?
Agile is that the best SDLC methodology and conjointly one in every of the foremost used SDLC within the tech trade as per the annual State of Agile report. At RnF Technologies, Agile is that the most loved software development life cycle model. Here’s why. Agile is very adaptive that making it totally different from all alternative SDLC.
Conclusion The software development life cycle is a resourceful tool for developing high-quality software products. This tool provides a framework for guiding developers in the process of software development. Organizations can use various SDLC strategies such as waterfall, V-model, iterative, spiral, and agile models. You should consider consulting with a resourceful IT company before embracing an SDLC approach for your team from the list above. DevOpsSchoolhas enough expertise to help you know how different models come in handy in certain business scenarios and industry environments. From our experience, we will guide you to the best fit for your software product.