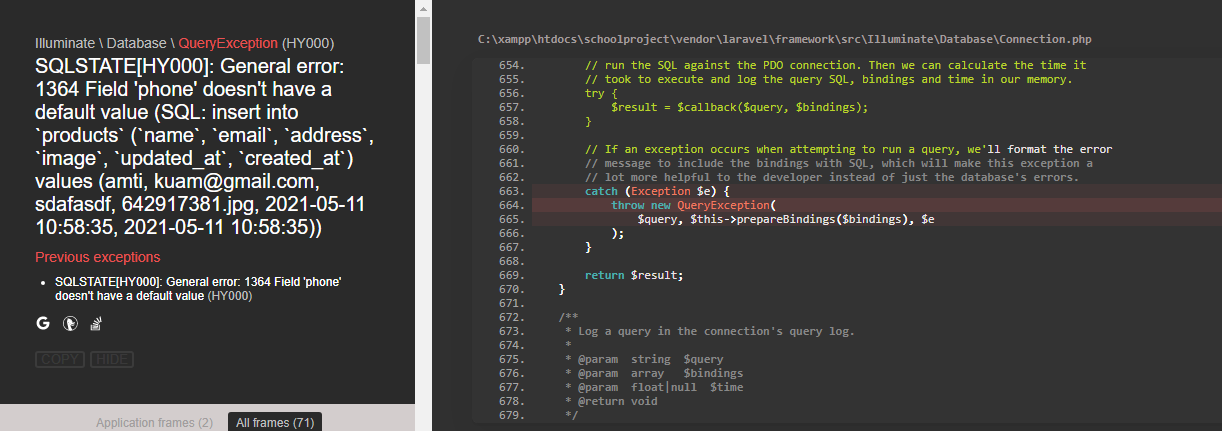
Data mining tools are software applications or platforms designed to discover patterns, relationships, and insights from large datasets. These tools employ various techniques from statistics, machine learning, and database systems to extract useful information from complex data.
Here are some popular data mining tools:
- RapidMiner
- Weka
- KNIME
- Orange
- IBM SPSS Modeler
- SAS Enterprise Miner
- Microsoft SQL Server Analysis Services
- Oracle Data Mining
- Apache Mahout
- H2O.ai
1. RapidMiner:
Incorporating Python and/or R in your data mining arsenal is a great goal in the long term. In the immediate term, however, you might want to explore some proprietary data mining tools. One of the most popular of these is the data science platform RapidMiner. RapidMiner unifies everything from data access to preparation, clustering, predictive modeling, and more. Its process-focused design and inbuilt machine learning algorithms make it an ideal data mining tool for those without extensive technical skills, but who nevertheless require the ability to carry out complicated tasks. The drag-and-drop interface reduces the learning curve that you’d face using Python or R, and you’ll find online courses aimed specifically at how to use the software.
Key features:
- Predictive Modeling (a technique for predicting the future.)
- Recognize the Present, revisit, and analyze the past.
- Provides RIO ( Rapid Insight online) webpage for users to share reports and visualizations among teams.
2. Weka:
Weka is an open-source machine learning software with a vast collection of algorithms for data mining. It was developed by the University of Waikato, in New Zealand, and it’s written in JavaScript. It supports different data mining tasks, like preprocessing, classification, regression, clustering, and visualization, in a graphical interface that makes it easy to use. For each of these tasks, Weka provides built-in machine-learning algorithms which allow you to quickly test your ideas and deploy models without writing any code. To take full advantage of this, you need to have a sound knowledge of the different algorithms available so you can choose the right one for your particular use case.
Key Features:
- If you have a good knowledge of algorithms, Weka can provide you with the best options based on your needs.
- Of course, as it is open source, any issue in any released version of its suite can be fixed easily by its active community members.
- It supports many standard data mining tasks.
3. KNIME:
KNIME (short for the Konstanz Information Miner) is yet another open-source data integration and data mining tool. It incorporates machine learning and data mining mechanisms and uses a modular, customizable interface. This is useful because it allows you to compile a data pipeline for the specific objectives of a given project, rather than being tied to a prescriptive process. KNIME is used for the full range of data mining activities including classification, regression, and dimension reduction (simplifying complex data while retaining the meaningful properties of the original dataset). You can also apply other machine learning algorithms such as decision trees, logistic regression, and k-means clustering.
Key features:
- Offers feature such as Social media Sentiment analysis
- Data and Tools Blending
- It is free and open-source, hence accessible to a large number of users easily.
4. Orange:
Orange is an Open-Source Data Mining Tool. Its components (referred to as widgets) assist you with a variety of activities, including reading data, training predictors, data visualization, and displaying a data table.vOrange can format the data it receives in the correct manner, which you can then shift to any desired position using widgets. Orange’s multi-functional widgets enable users to do Data Mining activities in a short period and with great efficiency. Learning to use Orange is also a lot of fun, so if you’re a newbie, you can jump right into Data Mining with this tool.
Key features:
- Beginner Friendly
- Has a very vivid and Interactive UI.
- Open Source
5. IBM SPSS Modeler:
IBM SPSS Modeler is a data mining solution, which allows data scientists to speed up and visualize the data mining process. Even users with little or no programming experience can use advanced algorithms to build predictive models in a drag-and-drop interface.
With IBM’s SPSS Modeler, data science teams can import vast amounts of data from multiple sources and rearrange it to uncover trends and patterns. The standard version of this tool works with numerical data from spreadsheets and relational databases. To add text analytics capabilities, you need to install the premium version.
Benefits are :
- It has a drag-and-drop interface making it easily operable for anyone.
- Very little amount of programming is required to use this software.
- Most suitable Data Mining software for large-scale initiatives.
6. SAS Enterprise Miner:
Statistical Analysis System is the abbreviation for SAS. SAS Enterprise Miner is ideal for Optimization, and Data Mining. It provides a variety of methodologies and procedures for executing various Analytic capabilities that evaluate the organization’s demands and goals. It comprises Descriptive Modeling (which can be used to categorize and profile consumers), Predictive Modeling (which can be used to forecast unknown outcomes), and Prescriptive Modeling (useful to parse, filter, and transform unstructured data). SAS Data Mining tool is also very scalable due to its distributed memory processing design.
Key features:
- Graphical User Interface (GUI): SAS Enterprise Miner offers an intuitive graphical user interface that allows users to visually design and build data mining workflows. The drag-and-drop interface makes it easy to create, edit, and manage data mining processes.
- Data Preparation and Exploration: The tool provides a comprehensive set of data preparation and exploration techniques. Users can handle missing values, perform data transformations, filter variables, and explore relationships between variables.
- Data Mining Algorithms: SAS Enterprise Miner offers a variety of advanced data mining algorithms, including decision trees, neural networks, regression models, clustering algorithms, association rules, and text mining techniques. These algorithms enable users to uncover patterns, make predictions, and discover insights from their data.
7. Microsoft SQL Server Analysis Services:
A data mining and business intelligence platform that is part of the Microsoft SQL Server suite. It offers data mining algorithms and tools for building predictive models and analyzing data.
key features:
- Data Storage and Management: SQL Server provides a reliable and scalable platform for storing and managing large volumes of structured data. It supports various data types, indexing options, and storage mechanisms to optimize data organization and access.
- Transact-SQL (T-SQL): SQL Server uses Transact-SQL (T-SQL) as its programming language, which is an extension of SQL. T-SQL offers rich functionality for data manipulation, querying, and stored procedures, enabling developers to perform complex operations and automate tasks.
- High Availability and Disaster Recovery: SQL Server offers built-in features for high availability and disaster recovery. It supports options like database mirroring, failover clustering, and Always On availability groups to ensure data availability and minimize downtime.
8. Oracle Data Mining:
Oracle Data Mining (ODB) is part of Oracle Advanced Analytics. This data mining tool provides exceptional data prediction algorithms for classification, regression, clustering, association, attribute importance, and other specialized analytics. These qualities allow ODB to retrieve valuable data insights and accurate predictions. Moreover, Oracle Data Mining comprises programmatic interfaces for SQL, PL/SQL, R, and Java.
Key features:
- It can be used to mine data tables
- Has advanced analytics and real-time application support
9. Apache Mahout:
Apache Mahout is an open-source platform for creating scalable applications with machine learning. Its goal is to help data scientists or researchers implement their own algorithms. Written in JavaScript and implemented on top of Apache Hadoop, this framework focuses on three main areas: recommender engines, clustering, and classification. It’s well-suited for complex, large-scale data mining projects involving huge amounts of data. In fact, it is used by some leading web companies, like LinkedIn or Yahoo.
key features:
- Scalable Algorithms: Apache Mahout offers scalable implementations of machine learning algorithms that can handle large datasets. It leverages distributed computing frameworks like Apache Hadoop and Apache Spark to process data in parallel and scale to clusters of machines.
- Collaborative Filtering: Mahout includes collaborative filtering algorithms for building recommendation systems. These algorithms analyze user behavior and item properties to generate personalized recommendations, making it suitable for applications like movie recommendations or product recommendations.
- Clustering: Mahout provides algorithms for clustering, which group similar data points together based on their attributes. It supports k-means clustering, fuzzy k-means clustering, and canopy clustering algorithms, allowing users to identify natural groupings in their data.
10. H2O.ai:
H2O.ai is an open-source platform for machine learning and data analytics. It provides a range of key features and capabilities that make it a popular choice for building and deploying machine learning models.
Key features:
- Scalability and Distributed Computing: H2O.ai is designed to scale and leverage distributed computing frameworks like Apache Hadoop and Apache Spark. It can handle large datasets and perform parallel processing to speed up model training and prediction.
- AutoML (Automated Machine Learning): H2O.ai includes an AutoML functionality that automates the machine learning workflow. It can automatically perform tasks such as data preprocessing, feature engineering, model selection, and hyperparameter tuning, making it easier for users to build accurate models without manual intervention.
- Broad Range of Algorithms: H2O.ai offers a wide variety of machine learning algorithms, including popular ones like generalized linear models (GLMs), random forests, gradient boosting machines (GBMs), deep learning models, k-means clustering, and more. This rich set of algorithms allows users to choose the most appropriate technique for their specific problem domain.