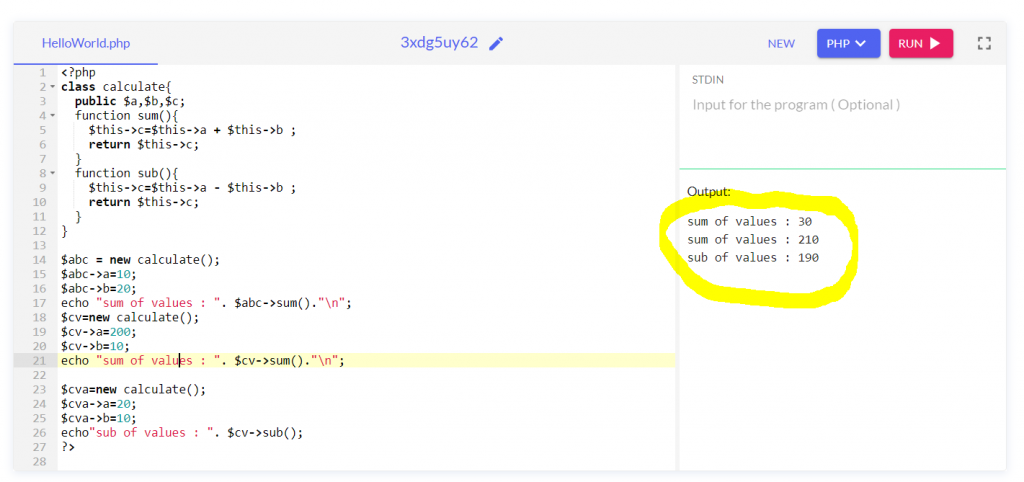
What is Traits?
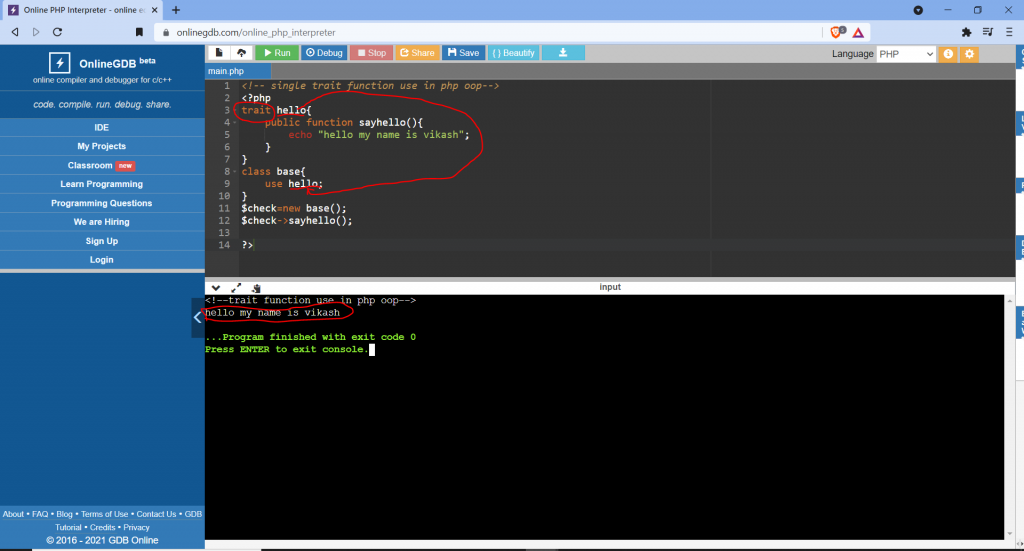
- Code is shortened by using Traits.
- One code is used everywhere just by writing the trait function.
Example :
Output:
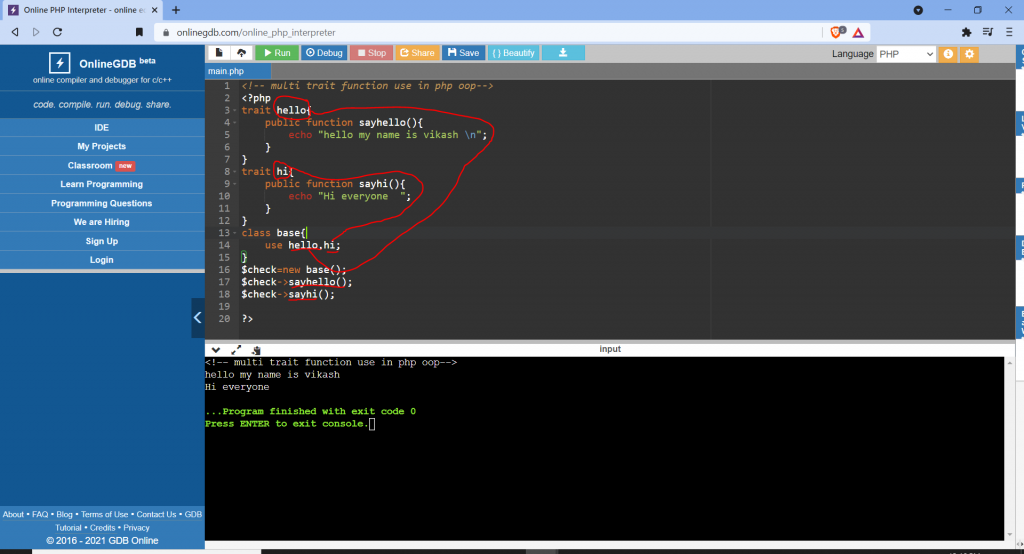
Multi traits use example:
Output:
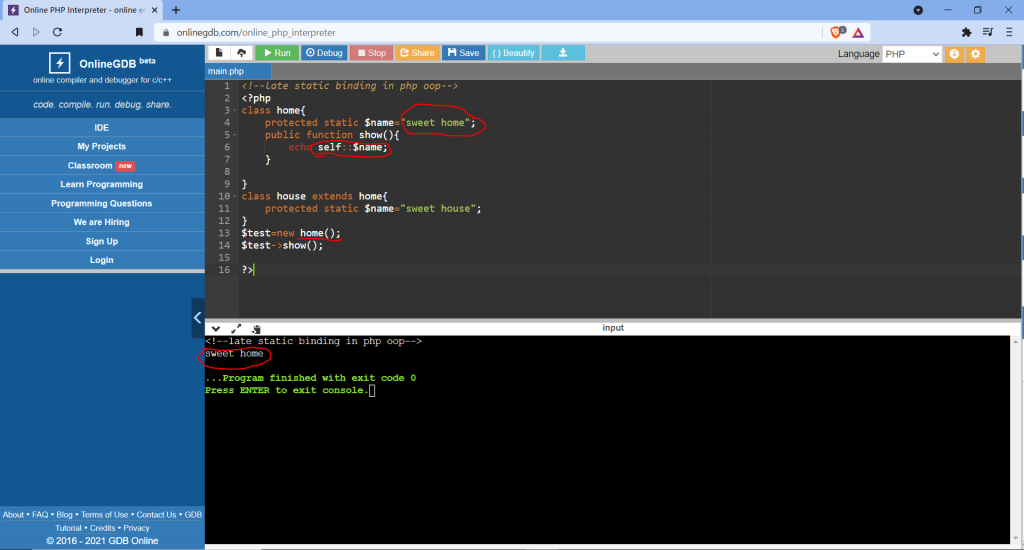
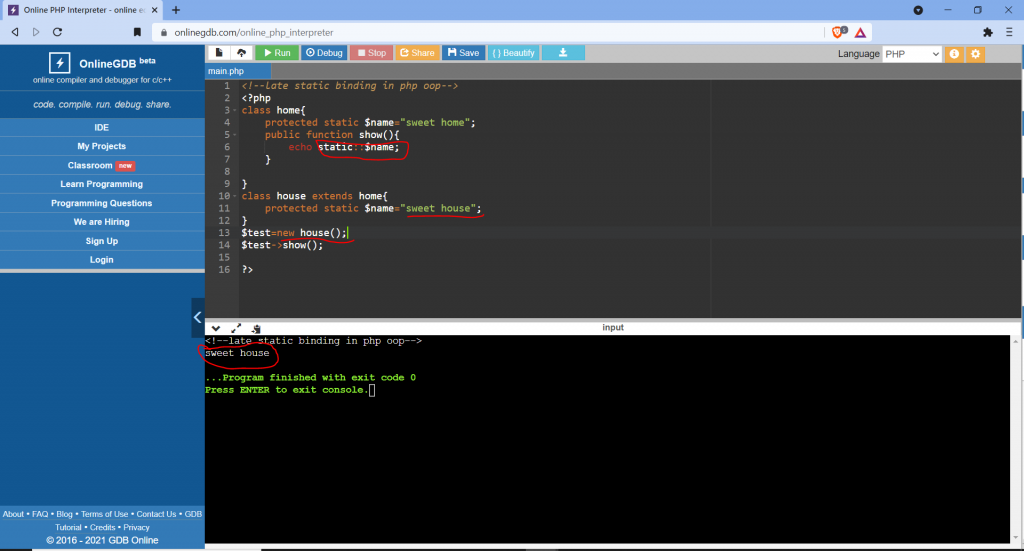
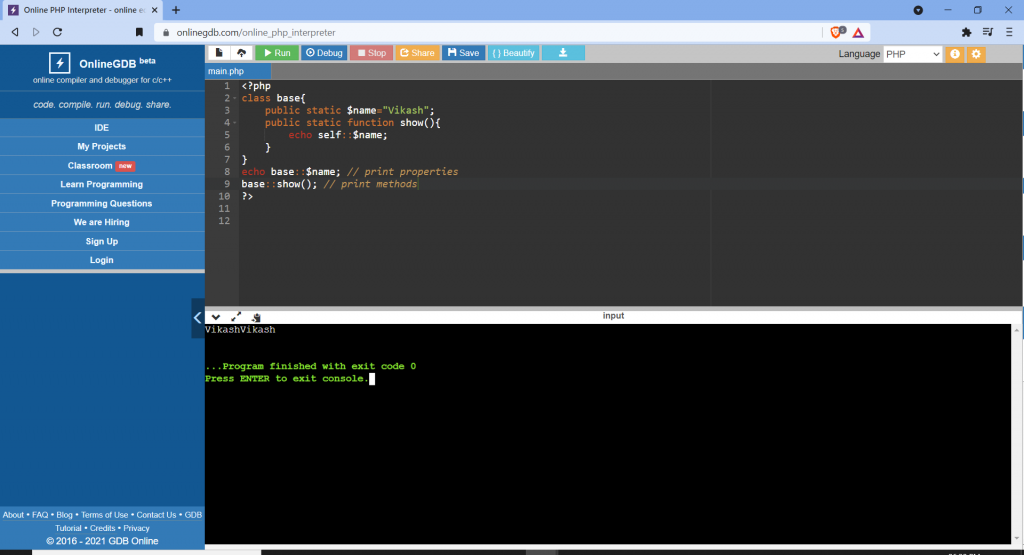
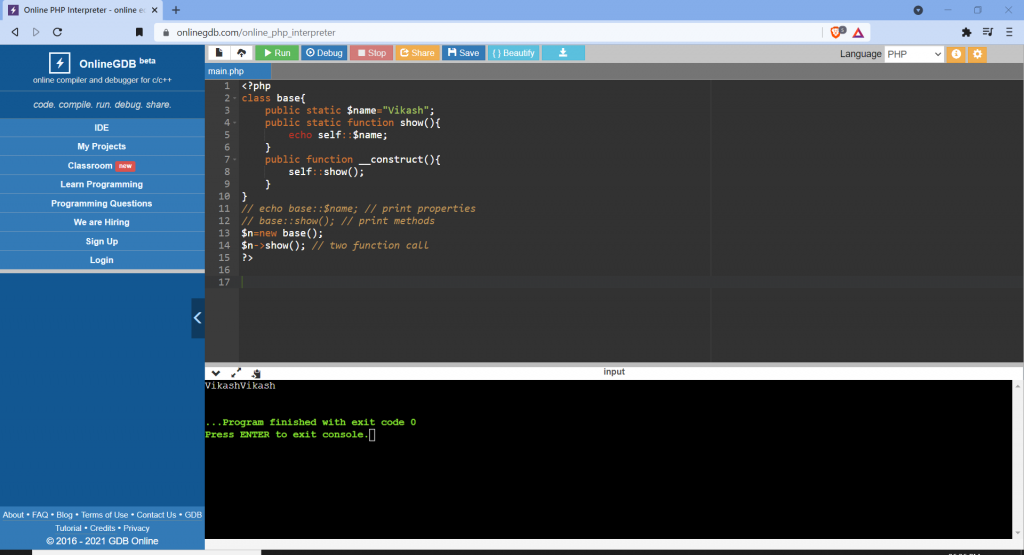
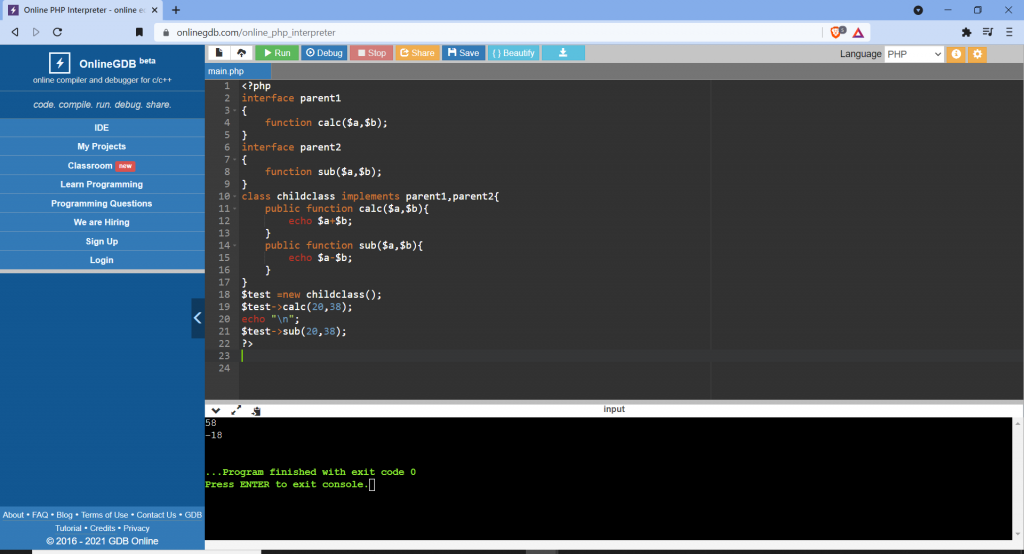
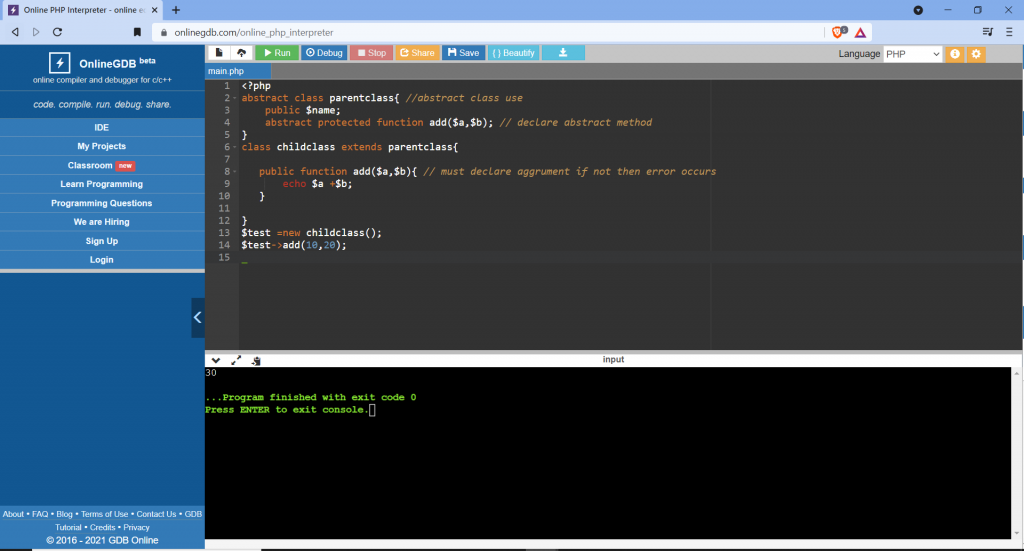
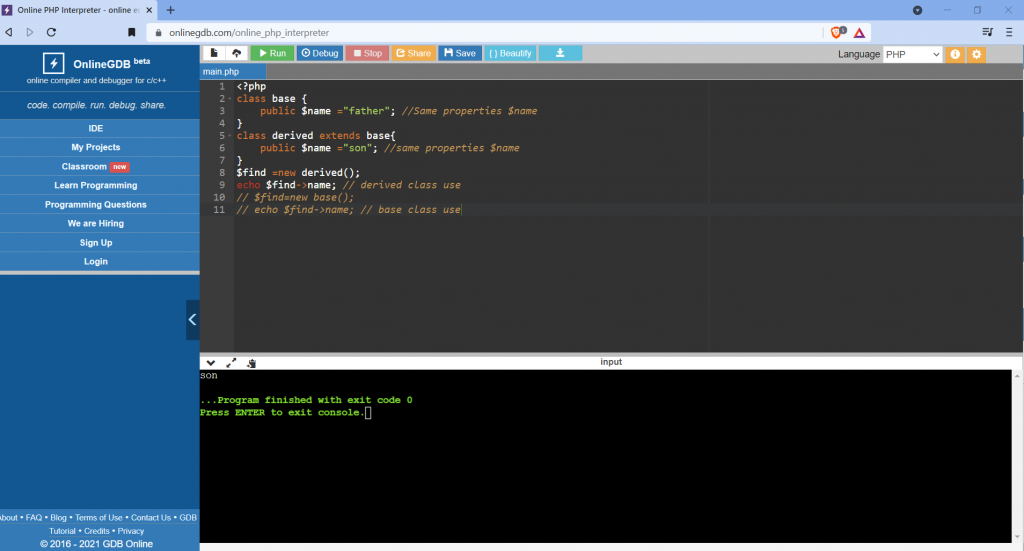
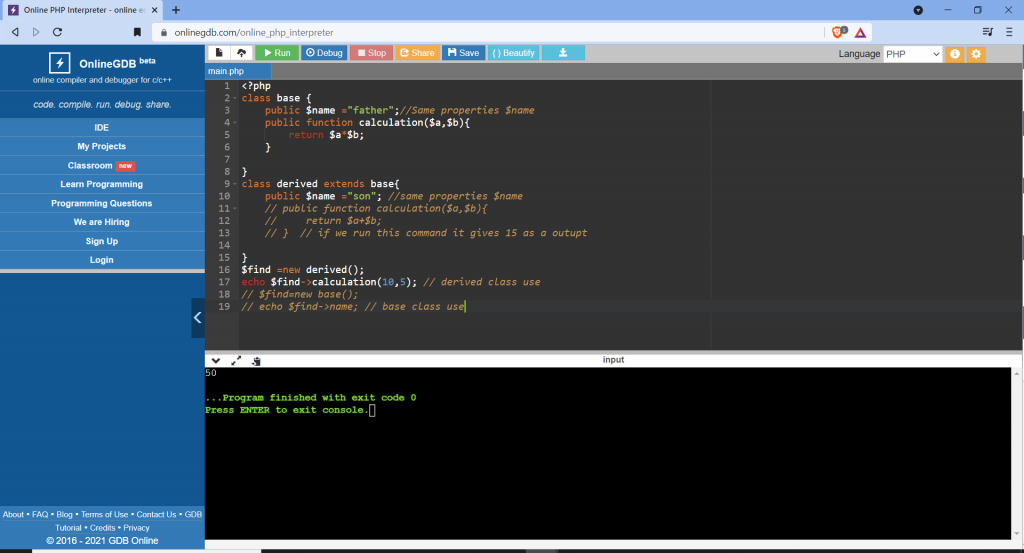
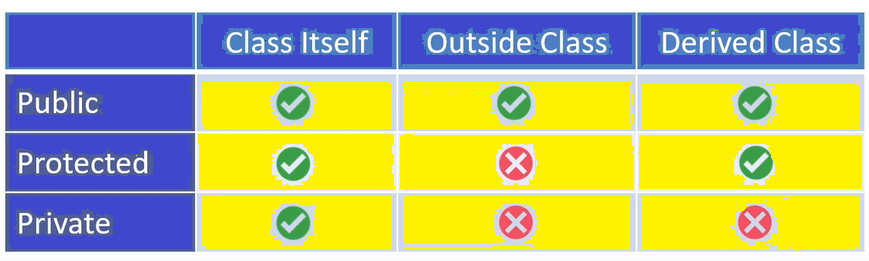
Restrictions on properties and methods.
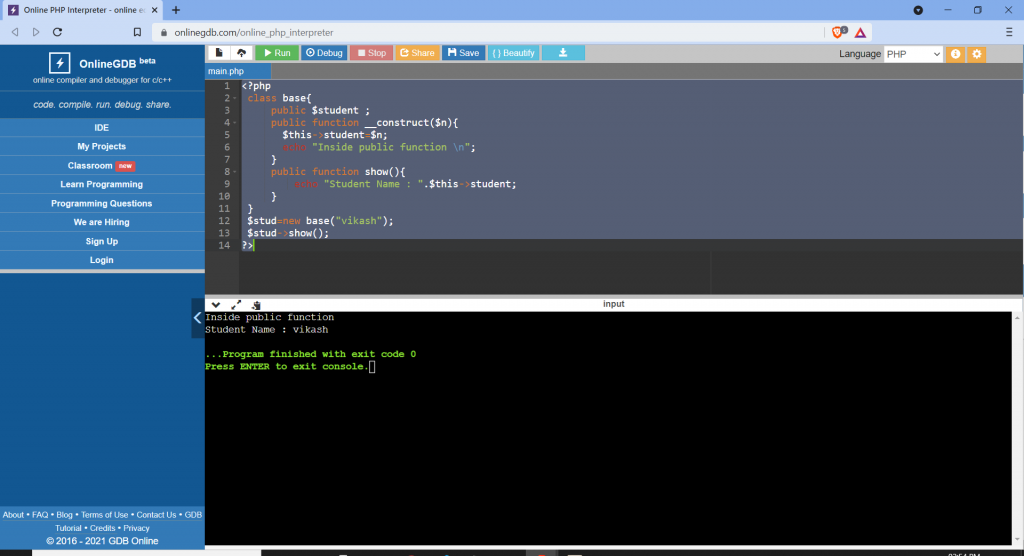
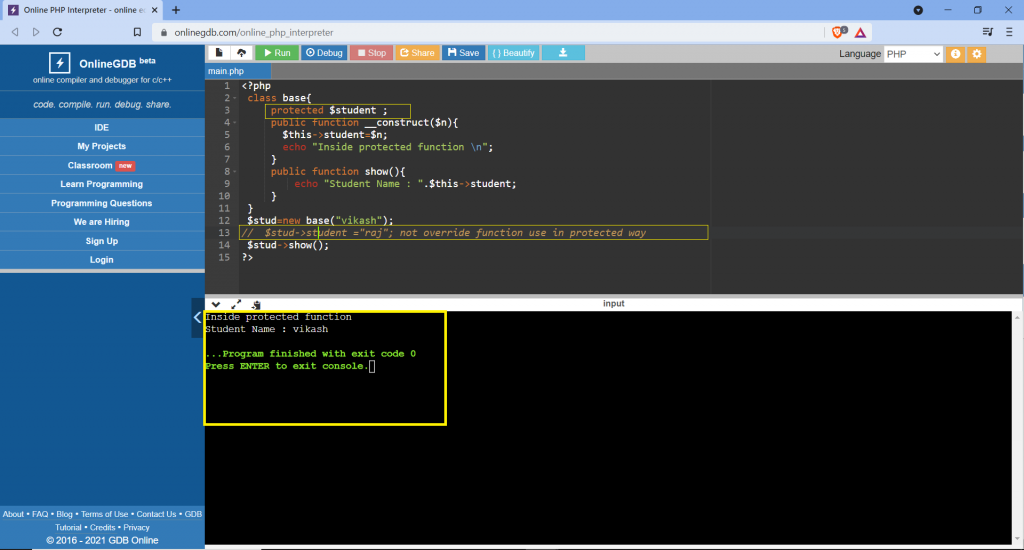
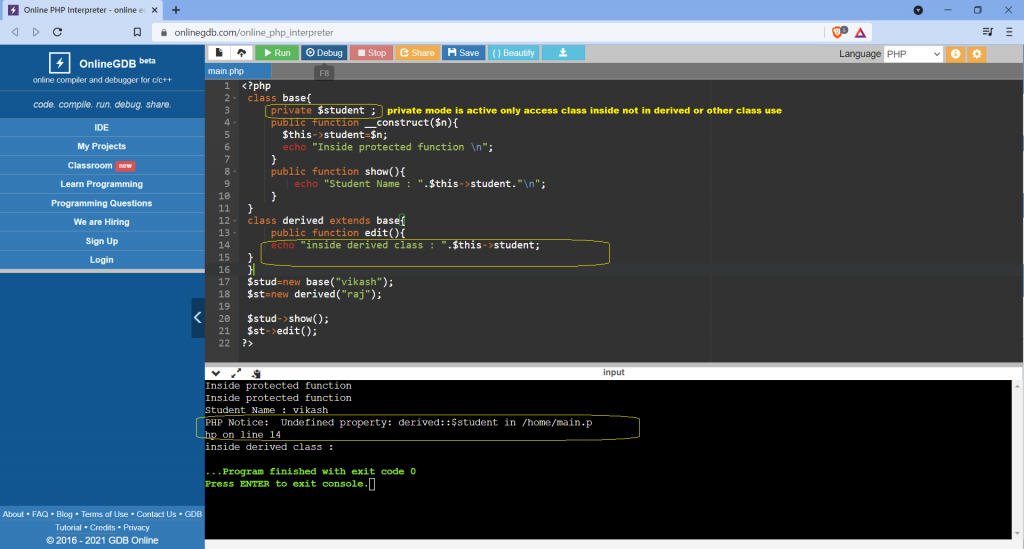
class school {
}
class students extends school {
}
$sch =new school (); // only use class school
$stu = new students (); // use both class school students (properties and methods)
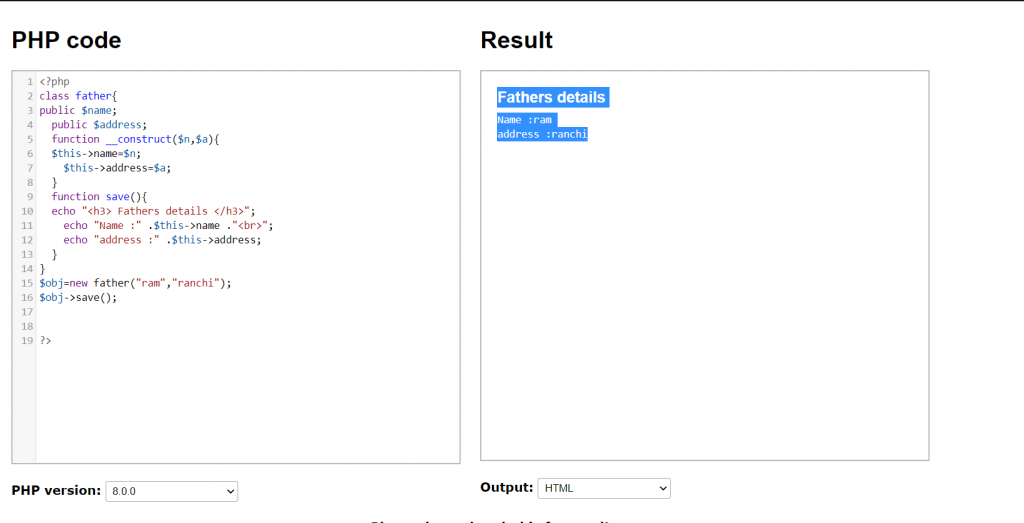
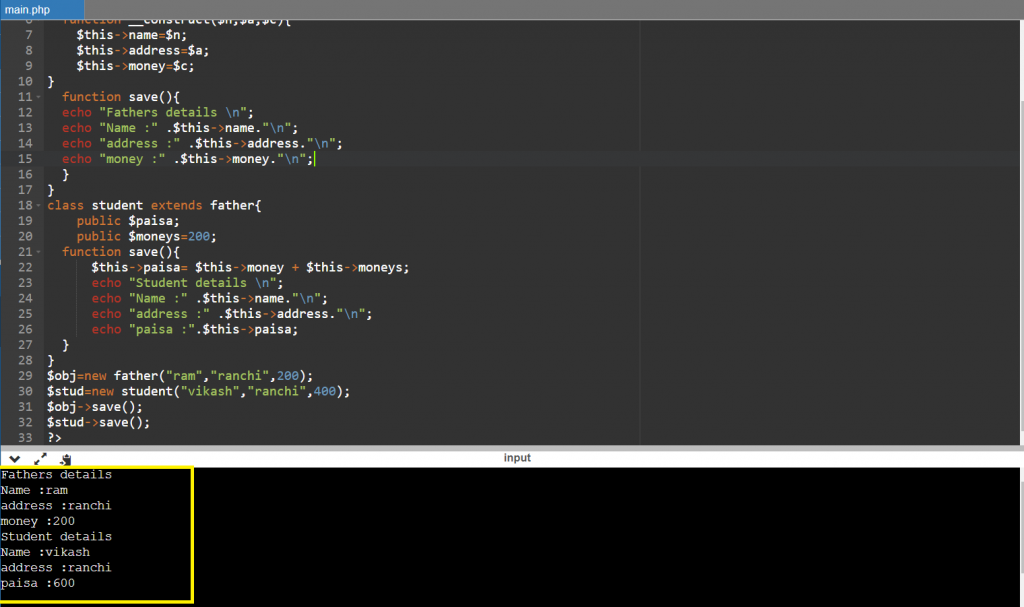
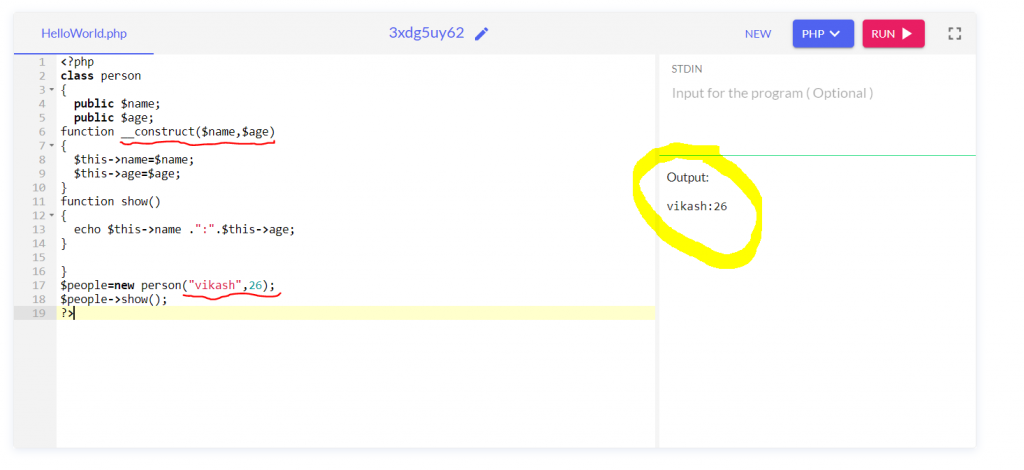
Constructor is a special type of function of a class which is automatically executed when object of that class is created. Constructor is also called as magic function because in php constructor is start usually with two underscore characters. It saves lot of time on big project.
function __constructor(){
body part;
}
properties like :-
$a;
$b;
$c;
$d;
Methods like :-
sum(){
$c=$a+$b;
return $c;
}