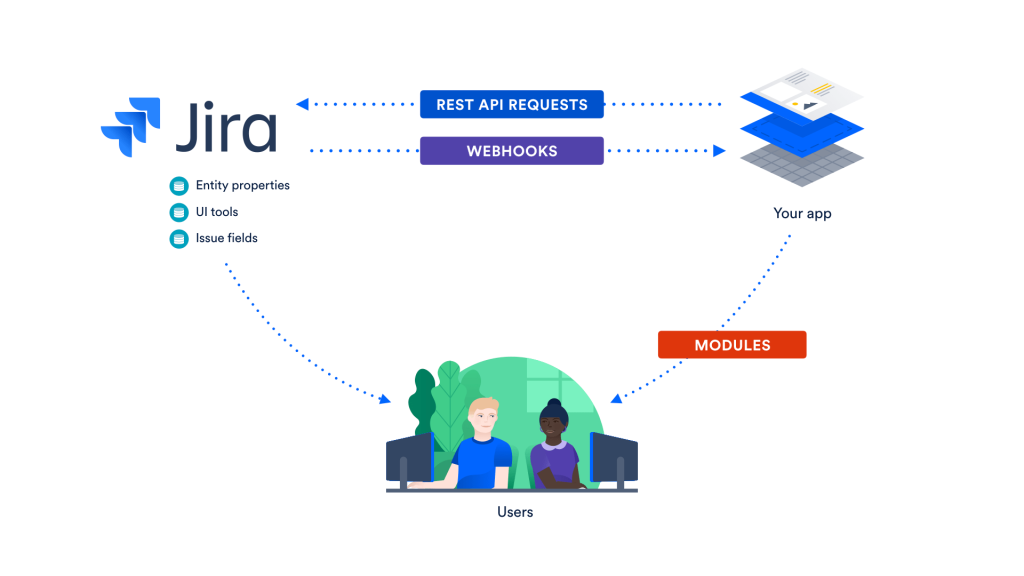
Hi dears, welcome to the course study of Jira. Today, through this article, I will explain to you how you will set up a Jira instance so that you can start to use Jira software for your projects. I have miscellaneous agenda for you. On which topics you will learn is types of Jira instance, what is the difference between server and Cloud instance? And how to create a cloud instance of Jira? So, let’s move forward to learn more about Jira concepts
Jira instance
Basically, there are two types of Jira instances, the first one is cloud and the second one is server. I will tell you what is the difference between the cloud and server instances and which one you should use if you are a beginner to learn about the Jira software. So, let’s move forward to learn about the cloud and the server instances.
Cloud vs server instance
Here I will discuss the cloud instance first. So, what is a cloud instance? In the cloud instance rather than installing and maintaining, your product on your own server Atlas Sian host and set up your Jira application on the cloud for you so, this is the cloud instance and according to me, this is the best instance for the beginner, who want to learn from the very beginning. It is very fast because it’s easy to set up and get started in minutes as soon as you sign up. You may start working and inviting the team members and the second one is reduced costs because it helps to save money on the physical hardware maintenance installation support and any other hidden administration cost as well. This is a cloud instance so, everything is on the cloud and there is no need to bear the cost of your own hardware. The third one is no need to upgrade because on the cloud you get immediate access to the latest version on Jira so, there is no need to upgrade the cloud instance. The fourth one is security, it is very secure because atlas Sian takes the responsibility to maintain the security and compliances of your data and organization so, I describe the benefits of the cloud instances but I want to tell you one more thing about you don’t have direct access to change the database structure, file system, or other server infrastructure because you have a cloud instance and atlas Sian already set up your cloud instance. So, they will not give you administrator access. Let’s learn more about the server instance. What is a server instance? In the server instance, basically, you install, host, and run the Atlas Sian’s product on your own hosting environment. So, basically, those teams will prefer that want to manage all the details on their own and are able to handle the complexity of setting up and hosting the product on their own server. So, if your organization is very big and you have a department of administrators. They can manage the administrator task of the Jira or the server so, you can go with the server version but you are working in a startup and you want to learn your own then go with a cloud one.
In this complete course, I will also use the cloud instance because as I already told you, it is very easy to set up and everyone can access it from anywhere but in the server instance may be the organization installed it on the internal environment so, you would not be able to access it from outside the organization but in the cloud instance, you may access anywhere as I told you I will explain the cloud version in this course so may be the people who are using the server one they will see some differences in the UI because the cloud and the server UI is different in the server we have the navigation on the top but in the cloud we have the navigation in the left hand side and many more other differences in the UI so as I told you the difference between the cloud and the server instances so let’s move forward and see how can you create the cloud instance of Jira so for creating the cloud instance of JIRA so, you will go to the atlas Sian website, there is an atlas Sian official website www.atlassian.com once you will click on the product tab then you can see the complete list of the atlas Sian the product but there you will go with the Jira software so, you will click on Jira software. It will take you on that page you may try it free then you can see the three plans and there will be cloud one. You may see try the product in the cloud and that is a free 7 days trail period you can go with any of the packages so, you will go there with any of the packages and you will go there with that one so, you will click on try it free, you will say that is a 7 day free cloud trial and it will give you the full access to all features, you can add the unlimited users and access to sales and technical support so, you will create the account there so you will use your ID and you will click on agree and sign up once you will end with the sign up process then you will see the screen where they will ask you to check your inbox and confirm your email ID so, you will go to your email so to verify that email you will click yes verify and it will redirect to you to the page if you want to select what type of team with do you work in then you can but for that you will skip and see the URL there that is a JIRA all sort of gentle that you have mentioned at the time of creating the account and you can invite your team with the help of the email address if you will enter the email address there and send the invitation then the people will get the email will get the invite and they can accept and use this environment and that JIRA instance for now you will skip that and there they will ask are you new to Jira or are you already experienced with Jira then you can find out for now. That will be the next page where you can see there are the two types of templates are available first one is the classic template and the second one is a next-generation template. You can see there the Kanban is scrum and the bug tracking three templates are available and these three templates come under the software category so if you will go and will select all types you can see there are many more templates are available which are related to business. In this course, that’s it for today this is a process where you can create the cloud instance.









